As with identifying the model’s concepts and variables, identifying relationships depends above all on the method the researcher adopts: qualitative or quantitative, inductive or deductive. Its aim is to determine whether there is a relationship between the model’s concepts (and variables), the nature of this relationship (causal or simple association) and the relationship’s sign (positive or negative).
1. Qualitative Method
Specifying qualitative relationships involves determining the elements that characterize the relationship. It is not a case of evaluating the relationship mathematically or statistically. However, nothing prevents the researcher from using a coding procedure to quantify the data before evaluating the relationship quantitatively.
1.1. Qualitative inductive method
In the case of inductive methods, Glaser and Strauss (1967) propose an ‘axial coding’ technique comprising a set of procedures by which the data is grouped together to create links between categories (Strauss and Corbin, 1990). The aim of axial coding is to specify a category (which the authors also call a phenomenon) according to the following categories:
- Causal conditions. These conditions, which the authors call ‘causal conditions’ or antecedent conditions, are identified with the help of the following questions: Why? When? How? Until when? There may be several causal conditions for one phenomenon.
- The context of all the phenomenon’s properties: its geographical and temporal position, etc. The researcher identifies the context by posing the following questions: When? For how long? With what intensity? According to which localization?, etc.
- Action/interaction strategies engaged to drive the phenomenon.
- Intervening conditions, represented by the structural context, which facilitate or restrict actions and interactions. These include time, space, culture, economic status, technical status, careers, history, etc.
- Consequences linked to these strategies. These take the form of events, and active responses to initial strategies. They are current or potential and can become causal conditions of other phenomena.
The phenomenon (or category) corresponds to the model’s central idea. It is revealed by the following questions: To what does the data refer? What is the aim of the actions and interactions?
1.2. Qualitative deductive method
As when specifying variables or concepts, researchers can use a qualitative/ deductive method to establish relationships between variables using the results of earlier research (available literature). Relationships established in this way can also be supplemented by other relationships stemming from initial observations in the field. So, before testing a model that was constructed a priori, researchers are advised to conduct several interviews, or collect information that will enable them to demonstrate other relationships than those stemming from the literature. The next stage involves operationalizing these relationships.
Example: Identifying relationships using a qualitative deductive method
In researching the relationship between sensemaking at a strategic level and organizational performance, Thomas et al. (1993) studied public hospitals in one US state and sought to relate the search for information to how this information is interpreted, the action then taken, and the results. Through an analysis of the literature, Thomas et al. were able to describe the relationships between their model’s different elements (see Figure 12.5).
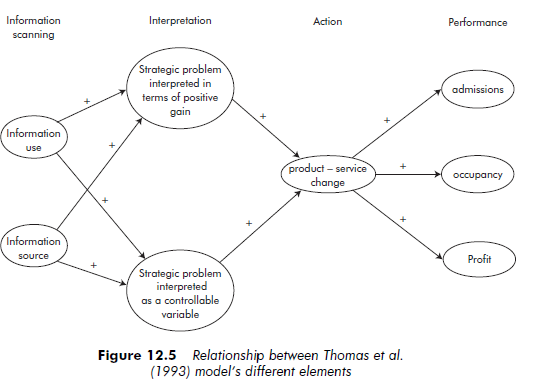
Information scanning was operationalized according to two variables: ‘information use’ and ‘information source’ (which could be internal or external). The concept of interpretation incorporated the two variables ‘positive gain’ and ‘controllability’. Strategic change was measured at the level of ‘product – service change’ over the period 1987 to 1989. Performance was measured using three variables: ‘occupancy’, ‘profit per discharge’ and ‘admissions’.
2. Quantitative Methods
Causal models provide a good example of the quantitative method of specifying causal relationships within a model. While quantitative methods are generally associated with a deductive approach, we will see that they can also be used in inductive research.
2.1. Quantitative deductive method
We can distinguish between two situations researchers may encounter in specifying the relationships between a model’s variables/concepts. When consulting the available literature, they may find specific hypotheses that clearly detail the nature and sign of the relationships between the variables/concepts. In this case, their main preoccupation will be to verify the validity of these hypotheses. The problem then essentially becomes one of testing the hypotheses or causal model. This question of testing causal models is dealt with in the fourth and final section of this chapter.
However, very often, researchers do not have a set of hypotheses or propositions prepared in advance about the relationships between the model’s concepts and variables. They then have to proceed to a full causal analysis. Although any of the qualitative techniques presented in the first part of this might be used, quantitative methods (that is, causal models) are more profitable.
Causal models can be defined as the union of two conceptually different models:
- A measurement model relating the latent variables to their measurement indicators (that is, manifest or observed variables).
- A model of structural equations translating a group of cause-and-effect relationships between latent variables or observed variables that do not represent latent variables.
Relationships between latent variables and their measurement indicators are called epistemic. There are three types: non-directional, reflective and formative. Non-directional relationships are simple associations. They do not represent a causal relationship but a covariance (or a correlation when variables are standardized). In reflective relationships, measurement indicators (manifest variables) reflect the underlying latent variable (that is, the latent variable is the cause of the manifest variables). In formative relationships, measurement indicators ‘form’ the latent variable (that is, they are the cause). The latent variable is entirely determined by the linear combination of its indicators. It can be difficult to determine whether a relationship is reflective or formative. For example, intelligence is a latent variable linked by reflective relationships to its measurement indicators, such as IQ. (Intelligence is the cause of the observed IQ.) However, the relationships between the latent variable, socio-economic status and measurement indicators such as the income or level of education are, by nature, formative (income and level of education effect economic status).
In the example in Figure 12.4, the ‘measurement model’ relates to measurement of the four latent variables ‘scope’, ‘resources’, ‘scale’ and ‘profitability’. The epistemic relationships are all reflective. Measurement models are analogous to factor analysis (on the manifest variables). Structural models look at causal relationships between latent variables, and are analogous to a series of linear regressions between latent variables (here, the relationships are between ‘scope’, ‘resources’ and ‘scale’, on the one hand, and ‘profitability’, on the other). Causal models can be presented as a combination of factor analysis (on the manifest variables) and linear regressions on the factors (latent variables). We can see how causal models are a generalization of factor and regression analyses.
Researchers who choose a quantitative process to specify relationships must systematically distinguish between the different kinds of relationship between their model’s variables (association, simple causality and reciprocal causality). In the language of causal models, association relationships are also called nondirectional relationships, and represent covariance (or correlations when the variables are standardized). Simple causal relationships are known as unidirectional, while reciprocal causal relationships are known as bi-directional. On a very general level, all relationships can be broken down into two effects: causal and non-causal (association). Causal effects, comprise two different effects: direct and indirect. A direct effect represents a direct causal relationship between an independent variable and a dependent variable. However, in causal models, one particular variable can, at the same time, be dependent on one direct effect and independent of another. This possibility for a variable to be both independent and dependent in one model goes to the heart of the notion of indirect effect.
Indirect effect is the effect of an independent variable on a dependent variable via one or several mediator variables. The sum of the direct and indirect effects constitutes the total effect. On-causal effects (association) also break down into two. First, there are association effects due to a common identified cause (that is, one or several variables within the model constitute the common cause of the two associated variables). Then, there are the non-analyzed association effects (that is, for various reasons, the researcher considers that the variables are associated). Researchers may do this when, for two related variables, they are unable to differentiate between cause and effect, or when they know that the two variables have one or several causes in common outside of the model. In causal models, non-analyzed associations translate as covariance (or correlations) and are represented by curves that may have arrow heads at each end.
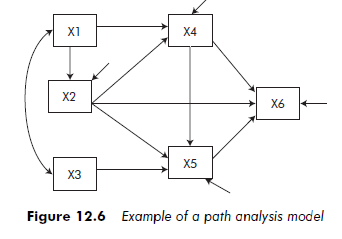
A model is said to be recursive if it has no bi-directional causal effect (that is, no causal relationship that is directly or indirectly reciprocal). While the terms can seem misleading, it should be noted that recursive models are unidirectional, and non-recursive models bi-directional. Recursive models occupy an important position in the history of causal models. One of the most well-known members of this family of methods, path analysis, uses only with recursive models. The other major characteristic of path analysis is that it only considers manifest variables. Path analysis is a case in point among causal models (Maruyama, 1998). Figure 12.6 presents an example of a path analysis model.
Identifying causal relationships in the framework of a quantitative approach can be more precise than just specifying the nature of these relationships (association, unidirectional or bi-directional). It is also possible to fix the sign of the relationships and even their intensity. Equality or inequality constraints may be taken into account. For example, the researcher may decide that one particular relationship is equal to a given fixed value (0.50, for instance), that another should be negative, that a third will be equal to a fourth, which will be equal to double a fifth, which will be less than a sixth, etc. Intentionally extreme, this example illustrates the great flexibility researchers have when they quantitatively specify the relationships between variables and concepts in a causal model.
2.2. Quantitative inductive methods
Quantitative methods can be used inductively to expose causal relationships between variables or concepts. By analyzing a simple matrix of correlations between variables, researchers can draw out possible causal relationships (between pairs of variables that are strongly correlated). It is also possible to make exploratory use of ‘explanatory’ statistical methods (for example, linear regression or analysis of variance) to identify statistically significant ‘causal’ relationships between different variables. However, explanatory methods are a case in point in terms of causal methods, and we prefer here to discuss the subject more generally.
Joreskog (1993) distinguishes between three causal modeling situations: confirmation, comparison and model generation. In the strictly confirmatory situation, researchers build a model which they then test on empirical data. When the test results lead to the model being rejected or retained, no other action is taken. It is very rare for researchers to follow such a procedure. The two other situations are much more common. In the alternative models situation, researchers start off with several alternative models. They evaluate each one using the same set of data and then compare them so as to retain the best ones. This is common when concurrent theories exist and when the area of interest has not yet reached a mature phase or there is uncertainty about the relationships between variables and concepts. In model generation, researchers begin with an already determined model, test it on a set of relevant data and then refine it (in particular, by eliminating the non-significant relationships and adding significant relationships omitted earlier). Aaker and Bagozzi (1979) make the following observation: while, ideally, a single model of structural equations corresponds to a given theory and researchers then calculate that model’s parameters, the situation is often different in practice. Most often, researchers begin with an initial version of the model of structural equations which they then test and improve iteratively before gradually obtaining a satisfactory version. According to Aaker and Bagozzi, this phenomenon arises because of the immaturity of the theories involved, the complexity of the management problems and the presence, at every stage of the research process, of uncertainties which translate as measurement errors.
While the strictly confirmatory situation is more in keeping with a deductive process, model generation and alternative models are totally compatible with an inductive approach. But as the existence of a (statistically significant) relationship does not mean there is necessarily a causal effect, researchers must always supplement their exploratory quantitative analyses with theoretical causal analysis.
Source: Thietart Raymond-Alain et al. (2001), Doing Management Research: A Comprehensive Guide, SAGE Publications Ltd; 1 edition.
Wow, this piece of writing is nice, my sister is analyzing these things, therefore I am going to tell her.
Very good information. Lucky me I came across your website by
chance (stumbleupon). I have saved it for later!
There’s definately a lot to find out about this topic.
I really like all of the points you made.
Good article. I’m facing some of these issues as well..