1. What Is ‘Data’?
‘Data’ is conventionally seen as forming the premises of theories. Researchers seek out and gather information – data – which can then be processed, using methodical instrumentation, to produce results and to improve on or to replace existing theories. However, two unstated and questionable propositions are hidden behind this commonsense understanding of data. The first is that data precedes theory. The second, arising from the first, is that data exists independently of researchers, who simply ‘find’ it and ‘compile’ it in order to impose their processes on it. The grammar of research only endorses such assumptions, as we conventionally distinguish between the phases of collecting, processing and analyzing data. It is as if, quite naturally, items of data were objects existing independently from their collection, processing and analysis. It is obvious that this proposition is both false and true. It is false because data does not precede theory, but is at once the medium and the continuing purpose for it. We use data just as much as we produce it, whether at the start of our theoretical reflection or closer to its completion.
Data is both a repository for and a source of theorization. Above all, the datum is a premise; a statement in the mathematical sense, or an accepted proposition. Its acceptance can be stated openly or implicitly – information can be presented in such a way that it implicitly carries the status of truth. This acceptance is essentially a convention that enables researchers to construct and to test propositions. The fact that this convention might be true or false, in a general sense, has no bearing on its scientific truth. By its acceptance, ‘data’ is given the status of assertions that allow researchers to continue their work without having to struggle over the truth value of the statements they make. Data frees researchers from having to believe in each proposition they put forward. It allows them to put ontological questions aside, or at least to relegate them to the background, so that they can operationalize their research process.
1.1. Data as a representation
Individual data items are accepted representations of a reality that we are not able to grasp empirically (through the senses) or theoretically (through abstract thought). The main reason for this is that reality cannot be reduced to a smaller part capable of expressing it in its entirety. The fact of having ‘lived through’ a reality does not mean that one possesses that reality, but more that one has grasped certain aspects of it to a greater or a lesser degree of intensity. The metaphor of a car accident can help us here to more fully understand this paradox. Anyone can ‘describe’ an accident, to differing degrees of exactitude, but to those who have lived through it there is an additional dimension that cannot be expressed. Two people who have survived the same car accident will have two different experiences of this single event, which can be considered as a shared reality. Their shared experience of the same event will have produced two distinct sets of data; sets that differ from each other, and differ even more from the description of the event by a person who did not experience it.
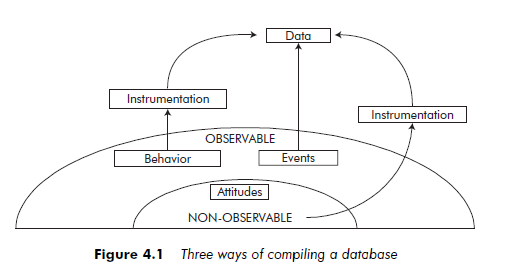
One could easily argue against the validity of this example by suggesting that qualitative data – that is, built up from accounts, descriptions and transcriptions of experiences – makes these differences obvious. However, the quantitative or qualitative nature of the data does not fundamentally change the problem. If we ask the two people involved in the accident to evaluate on scales of 1 to 5 the various sensations they had felt during the accident, we would still end up with different perceptions of the same reality. This could mean that (a) the reality of the accident was different for the two participants, or that (b) translation of a single reality by two different actors, by means of scales, can give different results. In both cases, the researcher will have integrated the ‘data’; that is, he or she will have accepted that one or the other means of representing the phenomenon (using scales, or anecdotal) is a suitable method of constructing data. Thus the status of ‘data’ is partly left to the free choice of the researcher. A researcher could consider an event that can be directly observed can itself constitute a datum, without the intermediary of instruments to transform stimuli into codes or numbers (for example, via categorization or the use of scales). A second way of compiling data is needed when researchers confront phenomena that are not directly observable, such as attitudes, in which case they have to rely on the use of instruments to transform these phenomena into a set of measurements. A common example is the use of a scale, through which actors can qualify their attitudes. This instrument can nevertheless be equally well applied to observable phenomena, such as behavior, in which case a third data compilation method is required (see Figure 4.1).
Even the transcription of an administrative committee meeting is simply a set of representations. Data-representations enable us to maintain a correspondence between an empirical reality and a system of symbols, and vice versa (Stablein, 1996: 514). Other researchers’ case studies can be used as ‘data’, for example. These case studies are representations, which can be compared to others collected, assembled or constructed by the researcher in pursuing the research question; although, whereas representations taken from earlier case studies form part of the research’s database, other types of representations belong to the system of symbols that enables theorization. From this we can see that while all data is a representation, every representation is not necessarily a datum (ibid.). Whether a representation is to be considered as a datum or not has more to do with the researcher’s epistemological position than any particular research methodology.
The scientific method traditionally accepts that the empirical world exists externally to the researcher, and that the researcher’s aim is to ‘discover’ it (Lakatos, 1965). This objective world is then immune to any subjective differences in the researchers who observe and record it. In studying the structure of scientific revolutions, Kuhn (1970) has, however, been able to show that scientific paradigms are sets of beliefs shared by communities of researchers, and that the data items used by researchers in defending or promoting their paradigm are ‘conceptions’: representations arising from the intersubjectivity of researchers sharing these beliefs.
1.2. Data and the researcher’s epistemological position
Data is at once a ‘discovery’ and an ‘invention’. When a dichotomy is established between these facets, discovery and invention, a bias can be introduced into the construction of theory. Researchers who, in an effort to maintain absolute objectivity, decide to limit data to ‘discoveries’ can, by deliberately avoiding a part of the data they consider to be too subjective, limit the creative part of their research. At the other extreme, a researcher who takes the position that there is no such thing as objective data, no reality beyond the interaction between the researcher and his or her sources – that observed reality is only an invention – risks blocking the progress of the research in paradoxical impasses, where ‘all is false, all is true’.
The compilation of data (its discovery-invention) is in fact a task involving evaluation, selection and choices that have important implications for the outcome of the research. Moreover, this process will signify the epistemological position of the research. A recognizable emphasis on the epistemological positioning of researchers runs throughout this book, as this is a question that cannot be evaded. Epistemological positioning is not a choice that is made once and held for the entire research process. The process of compiling research data is part of a continual movement back and forth between theory and its empirical foundations. Each time they move between the two, the question of what constitutes a datum returns researchers to the related issue of their epistemological position. Without this constant questioning, though, there is a risk of finding epistemological contradictions in the completed work: ‘constructivist’ research that treats data in a positivist manner or, vice versa, ‘positivist’ research that regards intersubjective representations as objective realities.
1.3. The subjectivity of data due to the reactivity of its source
The term ‘data’ is misleading. It implies the pre-existence, or the objective existence, external to the researcher, of a collection of facts and formal knowledge available and ready to be used. In fact, nothing is less objectively available than a datum. Data can be produced through an observer-observed relationship. When subjects are aware that their behavior is being observed, their attitudes are being evaluated, or events they are involved in are being studied, they become ‘reactive’ data-sources in the process of compiling a database (Webb et al., 1966).
Although the reactivity of the source can easily be shown in the context of collecting primary data in qualitative studies, it is not exclusively connected to that context. The fact that the data comes from a primary (firsthand) source or a secondary one (secondhand) is not a sufficiently discriminating criterion in terms of source reactivity. Researchers can collect behavioral data directly through non-participant observation without the subjects observed being aware of this observation and able to influence the data by reacting to it. On the other hand, organizational actors who give researchers access to secondary internal data, or reports or documents, can in fact intervene in the process of compiling the database. This intervention may be just as much through information they have highlighted as through information they have omitted or concealed. While it is usual, and quite rightly so, to emphasize the reactivity of primary data sources, secondary data is not exempt from this type of phenomenon.
The methodological approach to data, quantitative or qualitative, is not a satisfactory way to delimit situations of interactivity of data sources. Data collected through questionnaires or in-depth interviews can be affected by the withholding of information: the direction the data takes is in a sense that desired by the subjects who form its source. Whatever the approach, quantitative or qualitative, researchers are constrained to qualify and to maintain careful control over their presence during the stages of data collection and data processing (see Chapter 9).
The determining question is perhaps the following: ‘Is the data affected by the reactivity of its source to the observant researcher?’ In other words, it is useful to distinguish data obtained ‘obstrusively’ (with the subject-sources aware of its collection), from that obtained ‘unobstrusively’ (unknown to the subject- sources). Data collected ‘unobstrusively’ can be used to complement or to ‘tie together’ data that has been collected in an ‘obstrusive’ way, and is therefore marked by a certain subjectivity. This subjectivity may be due to the distortion induced by the subjects’ perceptual filters (Starbuck and Milliken, 1988) or to the selectivity of their memory. Data that has been collected ‘unobstrusively’ can also be useful when interpreting contradictions within data obtained from reactive sources (Webb et al., 1966; Webb and Weick, 1979).
2. Using Primary and Secondary Data
2.1. When to privilege primary or secondary data
If data is a representation, are researchers bound to creating their own system of representations – their own data – or can they be satisfied with available representations? Is theorization based on secondary data only of a lesser scientific standing than that which is ‘grounded’ in the field by the researcher himself or herself? In fact, many researchers in the social sciences tend to reply in the affirmative, sharply criticizing their colleagues who ‘theorize’ from other researchers’ data. Thus it is very often supposed that researchers cannot theorize from case studies that they have not conducted personally in the field.
But, although quite common, such a judgement is a received idea, and can be counterproductive (Webb and Weick, 1979: 652). In his 1993 article ‘The collapse of sense-making in organizations: the Mann Gulch disaster’, Weick uses Maclean’s Young Men and Fire (1992) as a secondary source. Maclean’s book draws on archival documents, interviews and observations to describe the deaths of 13 firemen in a fire, the magnitude of which had been tragically underestimated. Weick’s theorization was an important contribution to the organizational sciences, although he did not experience the events at first hand. It is certainly necessary to put such experiences into perspective. The theorization that Weick refines in his article is the fruit of many months of research, and Maclean’s book can be seen as just one piece in a work that is much broader and much more progressive in its scope.
We would not advise an inexperienced researcher to take on this kind of research without having first acquired, through fieldwork, a good understanding of data and how it is compiled. In this regard, collecting primary data gives researchers the opportunity to experience directly the ‘reality’ that they have chosen to study.
To sum up, the choice between using primary or secondary data should be brought down to a few fundamental dimensions: the ontological status of the data, its possible impact on the internal and external validity of the project, and its accessibility and flexibility.
Received ideas about primary data Weick’s theorization on the fire at Mann Gulch, and the acclaim his article has received, testify to the received ideas a scientific audience can hold on the standing of research according to the kind of data on which it is based. It is a great temptation to yield to ideology and to limit oneself to using primary data only, even when appropriate data is already available, out of a concern to conform to the audience’s expectations. The foremost received idea about primary data concerns its ontological status. There is a tendency to accord greater truth-value to research based on primary data. The argument is that the author has ‘witnessed’ the phenomena with his or her own eyes. But this ‘Doubting Thomas’ syndrome can give rise to excessive confidence in actors’ statements, and can lead researchers to produce theories that are not properly developed, precisely because they have not sufficiently distanced themselves from the field. Similarly, primary data is generally considered to be a superior source of internal validity, because the researcher will have established a system of data collection suited to the project and the empirical reality being studied. This belief in a superior internal validity arises from the fact that the researcher, in collecting or producing the data, is assumed to have eliminated rival explanations by allowing for them and monitoring for other possible causes. However, the relative liberty researchers have in instigating such controls, and the relative opacity they can generate in their instrumentation, does temper such a belief. The excessive confidence that stems from this autonomy in data production can, on the contrary, induce the researcher to be satisfied with weak outlines and to ignore important explanatory or intermediary variables.
On the other hand, it is usual to attribute to primary data a negative effect on the external validity of the research. Because the researcher will have been the only one to have ‘interacted’ with ‘his’ or ‘her’ empirical reality, a research work that is based solely on primary data can kindle doubt in its audience. But such doubt is unfounded, and represents a received idea that usually leads researchers to ‘compensate’ for their primary data with an excess of ad hoc secondary data. This secondary data is often introduced to cement the external validity of the research, when researchers realize that they are to some degree ‘out on a limb’.
Primary data is also often thought to be difficult to access, although very flexible. This is not always the case! But because researchers tend to think they cannot gain access to the primary data they need, they often give priority to available secondary data, whereas the project may warrant particular instrumentation and the production of specific data. Similarly, too much confidence in the supposed ‘flexibility’ of primary data can lead researchers to become bogged down in fieldwork which can turn out to be much less flexible than the literature would suggest. Actors can resist the efforts of the researcher, play token roles, or give the responses that they feel will please the researcher – and so continually, albeit in good faith, bias the study.
Received ideas about secondary data Secondary data is also the object of a certain number of received ideas regarding its ontological status, its impact on internal or external validity, and its accessibility and flexibility. The most persistent of these undoubtedly concerns secondary data’s ontological standing. Because it is formalized and published, secondary data often comes to be attributed with an exaggerated status of ‘truth’. Its objectivity is taken at face value, and its reliability is considered equivalent to that of the publication in which it appears. Thus greater integrity is accorded to information from a recognized and accepted source than to information from lesser-known sources, without even questioning the conditions of production of these different sets of data. This phenomenon is accentuated by the use of electronic media that supplies data in directly exploitable formats. Formalization of data in a ready-to-use format can lead researchers to take the validity of this data, which they are manipulating, for granted.
Similar received ideas exist about the impact secondary data has on the research’s internal validity. The apparently strict organization of available data can suggest that it would be easier to control the internal validity of research based on it. However, as Stablein reminds us (1996: 516), internal validity should be demonstrated through the validity of the constructs it uses, that is, by clarifying and justifying the connections between the construct and the operational procedure through which it is manipulated – although Podsakoff and Dalton (1987) found that only 4.48 per cent of authors provided proof of the validity of their constructs in the published articles they examined. The formalization of secondary data can thus be wrongly assimilated to an intrinsic soundness. This last received idea leads researchers to believe their research will somehow be made secure by the use of secondary data. But, by attributing an a priori degree of confidence to the secondary data they manipulate, researchers are in fact simply externalizing (by passing this responsibility to others) the risks connected to the internal validity of their work.
The same shortcomings apply to the use of secondary data to increase the validity of results and their generalization. External validity is also conditioned by the validity of the work the secondary data has been drawn from.
The greater accessibility of secondary data is another disputable received idea. Such a belief can give researchers an impression of the completeness of their research, convinced they have had access to all available data. The apparent ease of accessing secondary data can lead researchers either to be quickly inundated with too much data, or to be too confident that they have ‘gone over the whole question’.
Parallel to this is the common acceptance that secondary data is fairly inflexible (thus making such data difficult to manipulate), which can in turn cause researchers to believe that secondary data must be more reliable than primary data. This is, however, a naive belief – as the fact that secondary data is fixed and formalized does not in any way signify that the phenomena it describes are similarly fixed and formalized. In other words, the use of secondary data can bring with it greater exposure to a maturation effect (see Chapter 10).
We have pointed out the potential dangers of choosing which data is most appropriate to a study on the basis of received ideas about the different qualities of primary and secondary data. It is fallacious to build a research project based on qualities supposed to be intrinsic to these two types of data. The use of primary or secondary data does bring with it a certain number of constraints in the research process, although these are mainly logistic. The fact that data is primary or secondary entails specific precautions in the collection and analysis stages.
2.2. Constraints inherent to primary or secondary data
Collection constraints Primary data poses significant collection problems. To begin with, the researcher has to gain access to the field, then to maintain this field – that is, to preserve this access and regulate the interaction with respondents – whether the primary data is to be collected through surveys or interviews, or through direct observation (see Chapter 9). The use of primary data therefore necessitates the mastery of a complex system of interaction with the field. Poor handling of this can have consequences for the entire project. Conversely, the use of secondary data enables the researcher to limit this interaction with the field, but offers less scope in compiling a database appropriate to the research question. This task can be long and laborious. Often the collaboration of actors who can authorize access to certain external databases or can guide researchers in finding their way through the organization’s archives is required.
Analysis constraints Similarly, primary and secondary data each entail specific analysis difficulties. Distortions in an analysis can arise at different levels according to whether the data is primary or secondary.
The use of primary data essentially poses problems of controlling the interpretations that are developed from this data. Researchers are in effect ‘defendant and jury’, insofar as they themselves gather the data that they will later analyze. Researchers may sometimes implicitly pursue their model or their construct both when collecting their data (an instrumentation bias) and when analyzing it (by failing to eliminate other possible causes, or by focusing on the desired construct).
The analysis of secondary data involves another kind of constraint. If researchers are confronted with secondary data that is partial, ambiguous or contradictory, they can rarely go back to the source to complete or to clarify it. The researcher is in effect forced to question either people quoted in the archives, or those who collected the data. That is, they are compelled to collect primary data ad hoc. This is a costly process, and access to the individuals concerned is only possible in exceptional cases.
2.3. Combining primary and secondary data
Primary and secondary data are complementary at all stages of the research process. If primary data is incomplete, it can be supplemented by secondary data, for example historical, so as to better understand the background of an event, or to weigh the case study against information that is external to it. Conversely, research that is initially based on secondary data (for example, a statistical database on direct foreign investments) could be usefully backed up by primary data (such as interviews with investors). The major difficulty encountered here is that the researcher has to evaluate his or her own database. Researchers may realize during data analysis that their database was inadequate, which would then entail a return to the data collection phase, whether the data required is primary or secondary (see Figure 4.2).
Source: Thietart Raymond-Alain et al. (2001), Doing Management Research: A Comprehensive Guide, SAGE Publications Ltd; 1 edition.
26 Jul 2021
26 Jul 2021
26 Jul 2021
26 Jul 2021
26 Jul 2021
26 Jul 2021