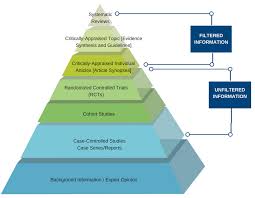
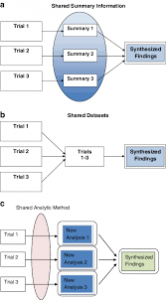
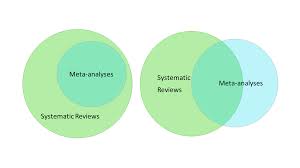
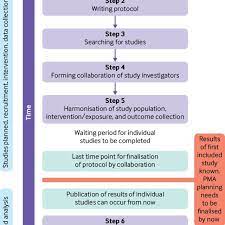
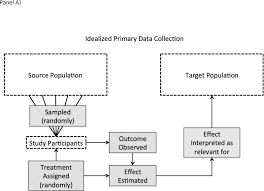
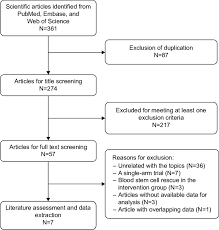
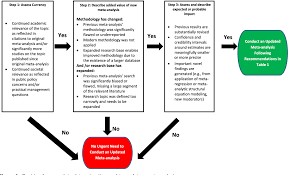
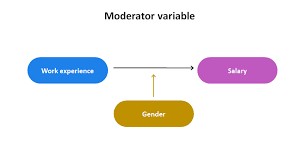
A Brief History of Meta-Analysis
In this section, I briefly outline the history of meta-analysis. My goal is not to be exhaustive in detailing this history (for more extensive treatments, see Chalmers, Hedges, & Cooper, 2002, Hedges, 1992, and Olkin, 1990; for a history intended for laypersons, see Hunt, 1997). Instead, I only hope to provide a basic overview