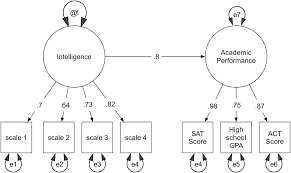
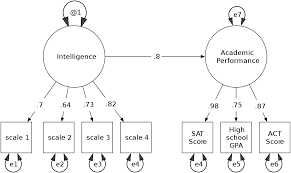
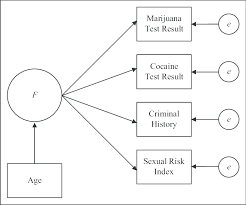
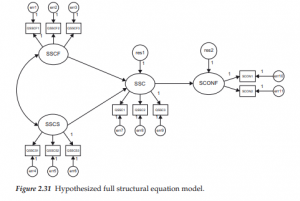
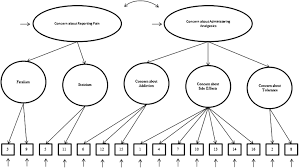
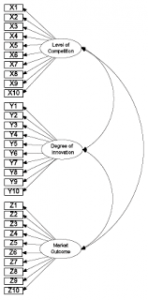
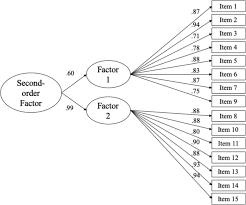
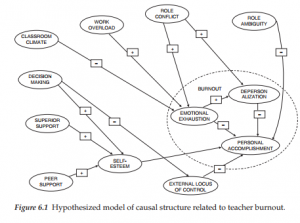
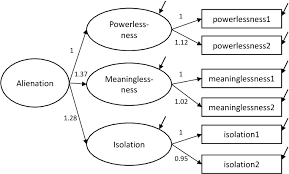
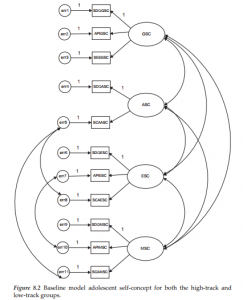
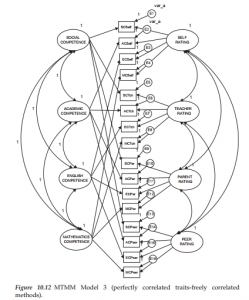
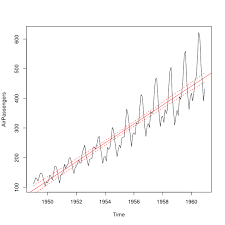
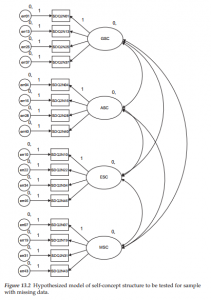
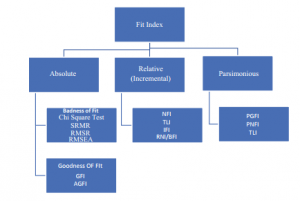
The General Structural Equation Model
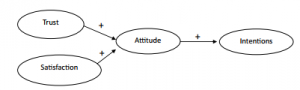
1. Symbol Notation Structural equation models are schematically portrayed using particular configurations of four geometric symbols—a circle (or ellipse), a square (or rectangle), a single-headed arrow, and a double-headed arrow. By convention, circles (or ellipses; CD) represent unobserved latent factors, squares (or rectangles; ) represent observed variables, single-headed arrows (→) represent the impact of