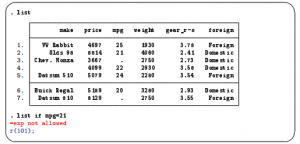
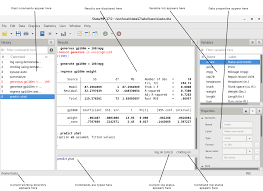
Quick Overview of Stata User Interface
Stata’s capabilities include data management, statistical analysis, graphics, simulations, regression, and custom programming. It also has a system to disseminate user-written programs that lets it grow continuously. This article introduces the core of Stata’s interface: its main windows, its toolbar, its menus, and its dialogs. 1. The windows The five main windows are the History,