1. Tests on Means
1.1. Comparing the mean m of a sample to a reference value μ0 when the variance σ2 of the population is known
Research question Does the mean m, calculated from a sample taken from a population with a known variance of σ2, differ significantly from a hypothetical mean μ0?
Application conditions
- The variance σ2 of the population is known (this is a very rare case!) but the mean m is not known (the hypothesis suggests it equals m 0).
- A random sample is used, containing n independent observations
- The size n of the sample should be greater than 5, unless the population follows a normal distribution, in which case the size has no importance. Actually, this size condition is to guarantee the mean of the sample follows a normal distribution (Sincich, 1996).
Hypotheses
The null hypothesis to be tested is H0: μ = μ0,
the alternative hypothesis is H1: μ # μ0 (for a two-tail test)
or Hp μ < μ0 (for a left-tail test)
or Hp μ # μ0 (for a right-tail test)
Statistic The statistic calculated is
![]()
It follows a standard normal distribution (mean = 0 and standard deviation = 1). This is called a z test or a z statistic.
Interpreting the test
- In a two-tail test, H0 will be rejected if Z < – Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if Z < – Za
- in a right-tail test, H0 will be rejected if Z > Za
where a is the defined significance level (or Type I error), and Za and Za/2 are the normal distribution values that can be found in the appropriate tables.
1.2. Comparing the mean m of a sample to a reference value when μ0 when the variance σ2 of the population is nknown
Research question Does the mean m, calculated from a sample taken from a population with an unknown variance σ2, differ significantly from a hypothetical mean μ0?
Application conditions
- The variance σ2 of the population is not known and has to be estimated from the sample. The mean m is also unknown (the hypothesis suggests it equals m 0).
- A random sample is used, containing n independent observations.
- The size n of the sample is greater than 30, unless the population follows a normal distribution, in which case the size has no importance.
Hypotheses
Null hypothesis, H0: μ = μ0,
the alternative hypothesis is H1: μ # μ0 (for a two-tail test)
or Hp μ < μ0 (for a left-tail test)
or Hp μ # μ0 (for a right-tail test)
Statistic The unknown variance (o2) of the population is estimated from the sample, with n – 1 degrees of freedom, using the formula
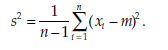
The statistic calculated is
![]()
It follows Student’s distribution with n – 1 degrees of freedom, and is called a t test or a t statistic.
Interpreting the test When n is large, that is, greater than 30, this statistic approximates a normal distribution. In other words:
![]()
The decision to reject or not to reject the null hypothesis can therefore be made by comparing the calculated statistic T to the normal distribution values. We recall that the decision-making rules for a standard normal distribution are:
- in a two-tail test, H0 will be rejected if Z <- Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if Z <- Za
- in a right-tail test, H0 will be rejected if Z > Za.
where a is the significance level (or Type I error) and Za and Za/2 are normal distribution values, which can be found in the appropriate tables.
But for smaller values of n, that is, lower than 30, the Student distribution (at n – 1 degrees of freedom) cannot be replaced by a normal distribution. The decision rules then become the following:
- In a two-tail test, H0 will be rejected if T <- Ta/2; n _ 1 or T > Ta/2; n _ 1
- in a left-tail test, H0 will be rejected if T <- Ta. n _ 1
- in a right-tail test, H0 will be rejected if T > Ta. n _ 1.
Example: Comparing a mean to a given value (variance is unknown)
This time, the sample is much larger, containing 144 observations. The mean found in this sample is again m _ 493. The estimated standard deviation is s _ 46.891. Is it still possible to accept a mean in the population p0 _ 500, if we adopt a significance level a of 5 per cent?
The relatively large size of the sample (n _ 144, and so is greater than 30) justifies the approximation of the statistic T to a normal distribution. Thus
![]()
which gives -1.79. The tables provide values of Z0.025 _ 1.96 and Z0.05 _ 1.64.
Two-tail test: As – Za/2 < T < Za/2 ( -1.96 < -1.79 < 1.96), the null hypothesis, stating that the mean of the population equals 500 (p = 500), cannot be rejected.
Left-tail test: as T < – Za (-1.79 < -1.64), the null hypothesis is rejected, to the benefit of the alternative hypothesis, according to which the mean in the population is less than 500 (p < 500).
Right-tail test: as T < Za (-1.79 < 1.64), the null hypothesis cannot be rejected.
As mentioned above, the major difficulty researchers face when carrying out comparison tests is to choose the appropriate test to prove their research hypothesis. To illustrate this, in the following example we present the results obtained by using proprietary computer software to analyze the above situation. For this example we will use the statistical analysis program, Statgraphics, although other software programs provide similar information.
The software carries out all the calculations, and even indicates the decision to make (to reject the null hypothesis or not) on the basis of the statistic T and the significance level a set by the researcher. In addition, it provides the p value, or the observed significance level. We have already mentioned the importance of the p value, which can provide more detailed information, and so refine the decision. In the first test (two-tail test), the null hypothesis is not rejected for a significance level of 5 per cent, but it would have been rejected if the Type I error risk had been 10 per cent. The p value (0.0753462) is greater than 5 per cent but less than 10 per cent. In the second test (left-tail test), the null hypothesis is rejected for a significance level of 5 per cent, while it would not have been rejected for a significance level of 1 per cent. The p value (0.0376731) is less than 5 per cent but greater than 1 per cent. Finally, in the last test (right-tail test), examining the p value (0.962327) suggests that there are good reasons for not rejecting the null hypothesis, as it is well above any acceptable significance level.
1.3. Comparing the difference of two means to a given value, when the variance of the two populations is known
Research question Is the difference between the two means p1 and p2 of two populations of known variances o2 and o2 significantly different from a given value D0 (for instance zero)?
Application conditions
- The variances o2 and o2 of the two populations are known. The means p1 and p2 are unknown.
- Both samples are random and contain n1 and n2 independent observations respectively.
- Either the mean for each population follows a normal distribution, or the size of each sample is greater than 5.
Hypotheses
Null hypothesis, H0: μ1 – μ2 = D0,
the alternative hypothesis is H1: μ1 – μ2 # D0 (for a two-tail test)
or Hp μ1 – μ2 < D0 (for a left-tail test)
or Hp μ1 – μ2 > D0 (for a right-tail test)
Statistic
The statistic calculated is
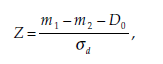
x1i = the value of variable X for observation i in population 1,
x2i = the value of variable X for observation i in population 2,
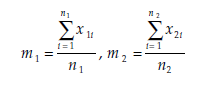
and
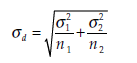
is the standard deviation of the difference (m1-m2).
Z follows a standard normal distribution.
Interpreting the test The decision rules are the following:
- In a two-tail test, H0 will be rejected if Z < -Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if Z < – Za
- in a right-tail test, H0 will be rejected if Z > Za.
1.4. Comparing the difference of two means to a given value, when the two populations have the same variance, but its exact value is unknown
Research question Is the difference between the two means m1 and m2 of two populations that have the same unknown variance σ2 significantly different from a given value D0 (for instance zero)?
Application conditions
- The two populations have the same unknown variance (σ2). The two means μ1 and μ2 are not known.
- Both samples are random and contain n1 and n2 independent observations respectively.
- Either the mean for each population follows a normal distribution, or the size of each sample is greater than 30.
- The hypothesis of equality of the variances is verified (see Section 3.2 of this chapter).
Hypotheses
Null hypothesis, H0: μ1 – μ2 = D0,
the alternative hypothesis is H1: μ1 – μ2 # D0 (for a two-tail test)
or Hp μ1 – μ2 < D0 (for a left-tail test)
or Hp μ1 – μ2 > D0 (for a right-tail test)
Statistic
The statistic calculated is:
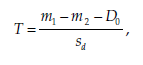
x1i = the value of the observed variable X for observation i in population 1,
x2i = the value of the observed variable X for observation i in population 2,
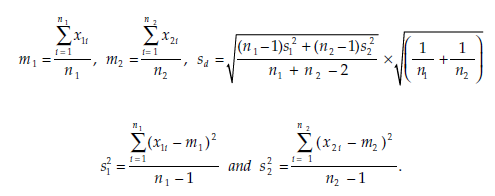
This statistic follows Student’s t distribution with n1 + n2 – 2 degrees of freedom.
Interpreting the test The decision rules are the following:
- in a two-tail test, H0 will be rejected if T <- Ta/2; n1 + n2 _ 2 or T > Ta/2; n1 + n2 _ 2
- in a left-tail test, H0 will be rejected if T <- T n1+n2 _ 2
- in a right-tail test, H0 will be rejected if T > T n1 + n2 _ 2.
When the sample size is sufficiently large (that is, n1 > 30 and n2 > 30), the distribution of the statistic T approximates a normal distribution, in which case
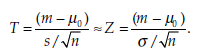
The decision to reject or not to reject the null hypothesis can then be made by comparing the calculated statistic T to the normal distribution. In this case, the following decision rules should apply:
- In a two-tail test, H0 will be rejected if T <- Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if T <- Za
- in a right-tail test, H0 will be rejected if T > Za.
1.5. Comparing two means, when the variances of the populations are unknown and differ
Research question Do the two means μ1 and μ2 of two populations of unknown variances and differ significantly from each other?
Application conditions
- The variances σ1 and σ2 of the two populations are unknown and different. The means μ1 and μ2 are unknown.
- Both samples are random and contain n1 and n2 independent observations respectively.
- For both populations, the mean follows a normal distribution.
- The two samples are of practically the same size.
- At least one of the samples contains fewer than 20 elements.
- The hypothesis of the inequality of variances is fulfilled (see Section 3.2 of this chapter).
Hypotheses
Null hypothesis, H0: μ1 = μ2,
the alternative hypothesis is H1: μ1 # μ2 (for a two-tail test)
or Hp μ1 < μ2 (for a left-tail test)
or Hp μ1 > μ2 (for a right-tail test)
Statistic Using the same notations as in Section 1.4 of this chapter, the statistic calculated is:
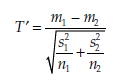
This statistic T’ is called an Aspin-Welch test. It approximates a Student T distribution in which the number of degrees of freedom v is the closest integer value to the result of the following formula:
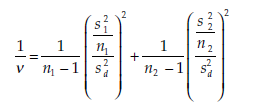
Interpreting the test The decision rules then become the following:
- in a two-tail test, H0 will be rejected if T’ <- Ta/2; v or T’ > Ta/2; v
- in a left-tail test, H0 will be rejected if T’ <- Ta; v
- in a right-tail test, H0 will be rejected if T > Ta. v.
1.6. Comparing k means (μk): analysis of variance
Research question Do k means, m1, m2… , mk observed on k samples differ significantly from each other?
This question is answered through an analysis of variance (Anova).
Application conditions
- All k samples are random and contain n1, n2… nk independent observations.
- For all k populations, the mean approximates a normal distribution with the same, unknown, variance (σ2).
Hypotheses
Null hypothesis, H0: π1 = π2 = … = πk,
alternative hypothesis, Hp the values of πi (i = 1, 2, … , k) are not all identical. This means that one single different value would be enough to reject the null hypothesis, thus validating the alternative hypothesis.
Statistic The statistic calculated is
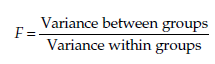
The statistic F follows a Fisher distribution with k – 1 and n – k degrees of freedom, where n is the total number of observations.
Interpreting the test The decision rule is the following:
H0 will be rejected if F > Fk _ 1; n _ k.
The analysis of variance (Anova) can be generalized to the comparison of the mean profiles of k groups according to j variables Xj. This analysis is called a Manova, which stands for ‘multivariate analysis of variance’. Like the Anova, the test used is Fisher’s F test, and the decision rules are the same.
1.7. Comparing k means (μk): multiple comparisons
Research question Of k means m1, m2… , mk observed on k samples, which if any differ significantly?
The least significant difference test, or LSD, is used in the context of an Anova when examination of the ratio F leads to the rejection of the null hypothesis H0 of the equality of means, and when more than two groups are present. In this situation, a classic analysis of variance will only furnish global information, without indicating which means differ. LSD tests, such as the Scheffe, Tukey, or Duncan tests, compare the groups two by two. These tests are all included in the major statistical analysis computer programs.
Application conditions
- All k samples are random and contain n1, n2… nk independent observations.
- For all k populations, the mean approximates a normal distribution with the same, unknown, variance (o2).
Hypotheses
Null hypothesis, H0: π1 = π2 = … = πk,
alternative hypothesis, H1: the values of πi (i = 1, 2, … , k) are not all identical. This means that one single different value would be enough to reject the null hypothesis, thus validating the alternative hypothesis.
Statistic
The statistic calculated is
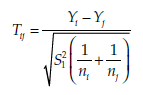
where Yi. is the mean of Group i, Y. the mean of group j, ni the number of observations of group i, nj the number of observations of group j, and S2 the estimation of the variance within each group. This statistic T. follows a Student distribution with n – k degrees of freedom, where n is the total number of observations. This signifies that the mean of all the two-by-two combinations of the k groups will be compared.
Interpreting the test The decision rule is the following:
H0 will be rejected if one Tj is greater than Ta/2; n _k. When Tij > Ta/2; n _ k, the difference between the means Yi. and Y- of the two groups i and j in question is judged to be significant.
1.8. Comparing k means (μk): analysis of covariance
Research question Do k means m1, m2… , mk observed on k samples differ significantly from each other?
Analysis of covariance permits the differences between the means of different groups to be tested, taking the influence of one or more metric variables, Xj called concomitants, into account. This essentially involves carrying out a linear regression to explain the means in terms of the X- concomitant variables, and then using an analysis of variance to examine any differences between groups that are not explained by the linear regression. Analysis of covariance is therefore a method of comparing two or more means. Naturally, if the regression coefficients associated with the explicative concomitant metric variables are not significant, an analysis of variance will have to be used instead.
Application conditions
- All k samples are random and contain n1, n2… nk independent observations.
- For all k populations, the mean approximates a normal distribution with the same, unknown, variance (o2).
- The choice of structure of the k groups should not determine the values of the concomitant metric variables.
Hypotheses
Null hypothesis, H0: π1 = π2 = … = πk,
alternative hypothesis, Hp the values of πi (i = 1, 2, … , k) are not all identical. This means that one single different value would be enough to reject the null hypothesis, thus validating the alternative hypothesis.
Statistic
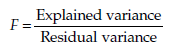
where the explained variance is the estimation made from the sample of the variance between the groups, and the residual variance is the estimation of the variance of the residues. This statistic F follows a Fisher distribution, with k – 1 and n – k – 1 degrees of freedom, n being the total number of observations.
Interpreting the test The decision rule is the following:
H0 will be rejected if F > Fk _ 1; n _k _ 1. The statistic F and the observed significance level are automatically calculated by statistical analysis software.
The analysis of covariance (Ancova) can be generalized to the comparison of the mean profiles of k groups according to j variables X. This is called a Mancova, for ‘multivariate analysis of covariance’. The test used (that is, Fisher’s F test) and the decision rules remain the same.
1.9. Comparing two series of measurements: the hotelling T2 test
Research question Do the mean profiles of two series of k measurements (m1, m2 … , mk) and (m’v m’2, … , mf), observed for two samples, differ significantly from each other?
The Hotelling T2 test is used to compare any two matrices or vectors, particularly correlation matrices, variance or covariance matrices, or mean-value vectors.
Application conditions
- The two samples are random and contain n1 and n2 independent observations respectively.
- The different measurements are independent and present a normal, multivariate distribution.
Hypotheses
Null hypothesis, H0: the two series of measurements present the same profile, alternative hypothesis, H1: the two series of measurements present different profiles.
Statistic
The statistic calculated is
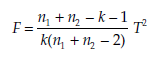
where T2 is Hotelling’s T2, k the number of variables, and n1 and n2 are the number of observations in the first and second sample.
The statistic F follows a Fisher distribution with k and n1 + n2 – k – 1 degrees of freedom.
Interpreting the test The decision rule is the following:
H0 will be rejected if F > Fk _ 1; n1 + n2 – k – 1.
2. Proportion Tests
2.1. Comparing a proportion or a percentage to a reference value π0: binomial test
Research question Does the proportion p, calculated on a sample, differ significantly from a hypothetical proportion π0?
Application conditions
- The sample is random and contains n independent observations.
- The distribution of the proportion in the population is binomial.
- The size of the sample is relatively large (greater than 30).
Hypotheses
Null hypothesis, H0: π = π0,
alternative hypothesis, H1: π # π0 (for a two-tail test)
or H1: π < π0 (for a left-tail test)
or H1: π > π0(for a right-tail test).
Statistic
The statistic calculated is
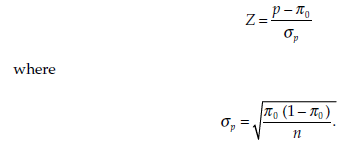
It follows a standard normal distribution.
Interpreting the test The decision rules are the following:
- in a two-tail test, H0 will be rejected if Z <- Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if Z < – Za
- in a right-tail test, H0 will be rejected if Z > Za.
2.2. Comparing two proportions or percentages p1 and p2 (with large samples)
Research question Do the two proportions or percentages p1 and p2, observed in two samples, differ significantly?
Application conditions
- The two samples are random and contain n1 and n2 independent observations respectively.
- The distribution of the proportion in each population is binomial.
- Both samples are large (n1 > 30 and n2 > 30).
Hypotheses
Null hypothesis, H0: π1 = π2,
alternative hypothesis, H1: π1 # π2 (for a two-tail test)
or H1: π1 < π2 (for a left-tail test)
or H1: π1 > π2 (for a right-tail test).
Statistic
The statistic calculated is
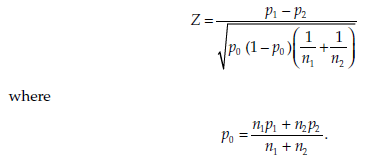
It follows a standard normal distribution.
Interpreting the test The decision rules are the following:
- in a two-tail test, H0 will be rejected if Z <- Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if Z <- Za
- in a right-tail test, H0 will be rejected if Z > Za.
2.3. Comparing k proportions or percentages pk (large samples)
Research question Do the k proportions or percentages p1, p2… , pk, observed in k samples, differ significantly from each other?
Application conditions
- The k samples are random and contain n1 n2… nk independent observations.
- The distribution of the proportion or percentage is binomial in each of the k
- All the samples are large (n1, n2… and nk > 50).
- The k proportions pk as well as their complements 1 – pk represent at least five observations, that is: pkxnk > 5 and (1 – pk) xnk > 5
Hypotheses
Null hypothesis, H0: π1 = π2 = … = πk,
alternative hypothesis, H1: the values of πi (i = 1, 2, … , k) are not all identical. This means that one single different value would be enough to reject the null hypothesis, thus validating the alternative hypothesis.
Statistic
The statistic calculated is
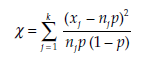
where xj = the number of observations in the sample j corresponding to the proportion pj, and
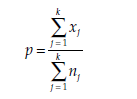
The statistic % follows a chi-square distribution, with k – 1 degrees of freedom.
Interpreting the test The decision rule is the following:
H0 will be rejected if
![]()
3. Variance Test
3.1. Comparing the variance σ2 to a reference value σ20
Research question Does the variance s2 calculated from a sample differ significantly from a hypothetical variance σ20 ?
Application conditions
- The sample is random and contains n independent observations.
- The distribution of the variance in the population is normal, the mean and standard deviation are not known.
Hypotheses
Null hypothesis, H0: σ2 = σ20,
alternative hypothesis, H1 σ2 # σ20 (for a two-tail test)
or H1 σ2 < σ20 (for a left-tail test)
or H1 σ2 > σ20 (for a right-tail test).
Statistic
The statistic calculated is
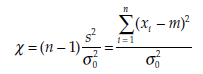
where σ20 is the given variance, s2 the variance estimated from the sample, and m the mean estimated from the sample. The statistic % follows a chi-square distribution with n – 1 degrees of freedom, which is written x2(n – 1).
Interpreting the test The decision rules are the following:

3.2. Comparing two variances
Research question Do the variances o0 and o2 of two populations differ significantly from each other?
Application conditions
- Both samples are random and contain n1 and n2 independent observations respectively.
- The distribution of the variance of each population is normal, or the samples are large (n1 > 30 and n2 > 30).
Hypotheses
Null hypothesis, H0: σ21 = σ22,
alternative hypothesis, H1 σ21 # σ22 (for a two-tail test)
or H1 σ21 < σ22 (for a left-tail test)
or H1 σ21 > σ22 (for a right-tail test).
Statistic
The statistic calculated is
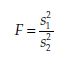
Where
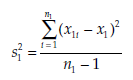
and
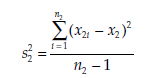
x1i = the value of variable X for observation i in population 1,
x2i = the value of variable X for observation i in population 2,
x1 = the mean estimated from the sample of variable X in population 1,
x2 = the mean estimated from the sample of variable X in population 2.
If required, the numbering of the samples may be inverted to give the numerator the greater of the two estimated variances,
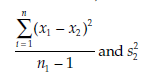
The statistic F follows a Fisher-Snedecor distribution, F(n1 – 1, n2 – 1). Interpreting the test The decision rules are the following:
- In a two-tail tesb H0 wib be rejected if F > Fa/2. n1 _ 1, n2 – 1 or F < F1 – a/2; n1 – 1, n2 – 1
- in a left-tail test, H0 will be rejected if F > Fa. n2 _ 1, n1 _ 1
- in a right-tail test, H0 will be rejected if F > Fa. n1 _ 1, n2 _ 1.
3.3. Comparing k variances: Bartlett test
Research question Do k variances σ21 , σ22 , ….σ2k observed in k samples, differ significantly from each other?
Application conditions
- All k samples are random and contain n1, n2… nk independent observations.
- The distribution of the variance of all k populations is normal.
- None of the observed variances equals zero.
Hypotheses
Null hypothesis, H0:
![]()
alternative hypothesis, H1: the values of of (i = 1, 2, … , k) are not identical
Statistic
The statistic calculated is
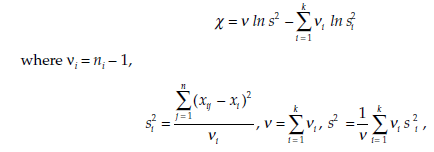
Xj = the value of variable X for observation j in population i,
xi = the mean of variable X in population i, estimated from a sample of size ni,
s2 = the variance of variable X in population i, estimated from a sample of size n.
The statistic % follows a chi-square distribution with v degrees of freedom.
Interpreting the test The decision rule is the following:
H0 will be rejected if
![]()
3.4. Comparing k variances: Cochran test
Research question Do k variances σ21 , σ22 , ….σ2k observed in k samples, differ significantly from each other?
More precisely, the Cochran test examines if the greatest of the k variances is significantly different to the k – 1 other variances
Application conditions
- The k samples are random and contain a same number n of independent observations.
- The variance in each of the k populations follows a normal distribution, or at least a uni-modal distribution.
Hypotheses
Null hypothesis, H0: σ21 =σ22 , =…σ2k
alternative hypothesis, H1: the values of σ2i (i = 1, 2, … , k) are not identical.
Statistic
The statistic calculated is
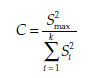
where the values of s2i 2 are the estimated variances calculated with n = n – 1 degrees of freedom, and S2 max is the greatest estimated variance within the k samples.
The statistic C is compared to the critical value Ca, as read from a table.
Interpreting the test The decision rule is the following: H0 will be rejected if C > Ca.
4. Correlation Tests
4.1. Comparing a linear correlation coefficient r to zero
Research question Is the linear correlation coefficient r of two variables X and Y significant – that is, not equal to zero?
Application conditions
- The observed variables X and Y are, at least, continuous variables.
Hypotheses
Null hypothesis, H0: p = 0,
alternative hypothesis, H1: p # 0 (for a two-tail test)
or H1: p < 0 (for a left-tail test)
or H1: p > 0 (for a right-tail test)
Statistic
The statistic calculated is
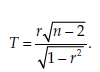
It follows a Student distribution with n – 2 degrees of freedom.
Interpreting the test The decision rules are the following:
- in a two-tail test, H0 will be rejected if T <- Ta/2; n _ 2 or T > Ta/2; n _ 2
- in a left-tail test, H0 will be rejected if T <- Ta. n _ 2
- in a right-tail test, H0 will be rejected if T > Ta. n _ 2.
For large values of n (n – 2 > 30), this statistic approximates a standard normal distribution. The decision to reject or not to reject the null hypothesis can then be made by comparing the calculated statistic T to values of the standard normal distribution, using the decision rules that have already been presented earlier in this chapter.
4.2. Comparing a linear correlation coefficient r to a reference value p0
Research question Is the linear correlation coefficient r of two variables X and Y, calculated from a sample, significantly different from a hypothetical reference value r 0?
Application conditions
- The observed variables X and Y are, at least, continuous variables.
Hypotheses
Null hypothesis, H0: p = p0,
alternative hypothesis, H1. p # p0 (for a two-tail test)
or Hy. p < p0 (for a left-tail test)
or Hy p > p0 (for a right-tail test)
Statistic
The statistic calculated is
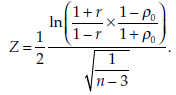
It follows a standard normal distribution.
Interpreting the test The decision rules are the following:
- in a two-tail test, H0 will be rejected if Z <- Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if Z <- Za
- in a right-tail test, H0 will be rejected if Z > Za.
4.3. Comparing two linear correlation coefficients, p 1 and p2
Research question Do the two linear correlation coefficients p 1 and p2 differ significantly from each other?
Application conditions
- The two linear correlation coefficients r1 and r2 are obtained from two samples of size n1 and n2 respectively.
Hypotheses
Null hypothesis, H0: p 1 = p 2,
alternative hypothesis, Hy p 1 # p2 (for a two-tail test)
or Hy p 1 < p2 (for a left-tail test)
or Hy p 1 > p2 (for a right-tail test).
Statistic
The statistic calculated is
It follows a standard normal distribution.
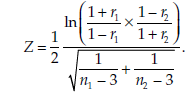
Interpreting the test The decision rules are thus the following:
- in a two-tail test, H0 will be rejected if Z <- Za/2 or Z > Za/2
- in a left-tail test, H0 will be rejected if Z <- Za
- in a right-tail test, H0 will be rejected if Z > Za.
5. Regression Coefficient Tests
5.1. Comparing a linear regression coefficient b to zero
Research question Is the linear regression coefficient P of two variables X and Y significant, that is, not equal to zero?
Application conditions
- The observed variables X and Y are, at least, continuous variables.
- P follows a normal distribution or the size n of the sample is greater than 30.
Hypotheses
Null hypothesis, H0: P = 0,
alternative hypothesis, H1: P # 0 (for a two-tail test)
or H1: P < 0 (for a left-tail test)
or H1: P > 0 (for a right-tail test).
Statistic
The statistic calculated is
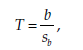
where b represents the regression coefficient P and sh its standard deviation, both estimated from the sample. The statistic T follows a Student distribution with n – 2 degrees of freedom.
Interpreting the test The decision rules are the following:
- in a two-tail test, H0 will be rejected if T <- Ta/2; n _ 2 or T > Ta/2; n _ 2
- in a left-tail test, H0 will be rejected if T <- Ta. n _ 2
- in a right-tail test, H0 will be rejected if T > Ta. n _ 2.
5.2. Comparing a linear regression coefficient β to a reference value β0
Research question Is the linear regression coefficient b of two variables X and Y significantly different from a reference value β0?
Application conditions
- The observed variables X and Y are, at least, continuous variables.
- P follows a normal distribution or the size n of the sample is greater than 30.
Hypotheses
Null hypothesis, H0: β = β0,
alternative hypothesis, Hp β # β0 (for a two-tail test)
or Hp β < β0 (for a left-tail test)
or Hp β > β0 (for a right-tail test).
Statistic
The statistic calculated is
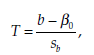
where b represents the regression coefficient P and s_ its standard deviation, both estimated from the sample. The statistic T follows a Student distribution with n – 2 degrees of freedom.
Interpreting the test The decision rules are the following:
- in a two-tail test, H0 will be rejected if T <- Ta/2; n _ 2 or T > Ta/2; n _ 2
- in a left-tail test, H0 will be rejected if T <- Ta. n _ 2
- in a right-tail test, H0 will be rejected if T > Ta. n _ 2.
5.3. Comparing two linear regression coefficients β and β in two populations
Research question Do the two linear regression coefficients β and β’, observed in two populations, differ significantly from each other?
This is again a situation in which the difference between two means b and _ with estimated variances s2b, and s2b, is tested. Naturally we must distinguish between cases in which the two variances are equal and cases in which they are not equal. If these variances differ, an Aspin-Welch test will be used.
Application conditions
- β and β’ represent the values of the regression coefficient in two populations, from which two independent, random samples have been selected.
- The observed variables X and Y are, at least, continuous variables.
Hypotheses
Null hypothesis, H0: β = β’,
alternative hypothesis, H1 : β # β’ (for a two-tail test)
or H1 : β < β’ (for a left-tail test)
or H1 : β > β’ (for a right-tail test).
Statistic
The statistics calculated and the interpretations of the tests are the same as for the tests on differences of means, described in parts 1.1 through 1.5 in this chapter.
In addition, it is possible to use the same kind of tests on a constant (P 0) of the linear regression equation. However, this practice is rarely used due to the great difficulties in interpreting the results. Similarly, more than two regression coefficients may be compared. For instance, the Chow test (Chow, 1960; Toyoda, 1974), which uses the Fisher-Snedecor distribution, is used to determine whether the coefficients of a regression equation are the same in two or more groups. This is called an omnibus test, which means that it tests whether the full set of equation coefficients are identical.
When comparing two groups, a neat and quite simple alternative to the Chow test is the introduction of a ‘dummy variable’ to the regression, indicating the group it belongs to. The original variables are multiplied by the dummy variable thus obtaining a set of new variables. The coefficients of the dummy variable represent the differences between the constants (P 0) for the two groups, and the coefficients of the new variables represent the differences between the coefficients of the explicative variables for the two groups. These coefficients can then be tested globally (as the Chow test does) or individually (see Sections 5.1 through 5.3 in this chapter) to identify which coefficient behaves differently according to the group.
Source: Thietart Raymond-Alain et al. (2001), Doing Management Research: A Comprehensive Guide, SAGE Publications Ltd; 1 edition.
Hi, Neat post. There’s a problem together with your website in internet explorer, may
test this? IE nonetheless is the market chief and a good element of other people will miss
your wonderful writing due to this problem.
Asking questions are truly nice thing if you are not understanding something entirely, however
this paragraph gives good understanding yet.
Hi, I do think this is a great website. I stumbledupon it 😉 I may revisit yet again since I
book marked it. Money and freedom is the best way to change, may you be rich and
continue to guide others.