Some have recommended that meta-analysts code for study quality and then either (1) include only studies meeting a certain level of quality or (2) evaluate quality as a moderator of effect sizes.2 This recommendation is problematic, in my view, because it assumes (1) that “quality” is a unidimensional construct and (2) that we are always interested in whether this overarching construct of “quality” directly relates to effect sizes. I believe that each of these assumptions is inaccurate, as I describe next.
1. The Multidimensional Nature of Study Quality
Study quality can be defined in many ways (see Valentine, 2009; for an example scoring instrument see Valentine & Cooper, 2008). At a broad level, you can consider quality in terms of study validity, specifically internal, external, construct, and statistical conclusion validity (Cook & Campbell, 1979; Shad- ish et al., 2002). Of course, within each of these four broad levels, there exist numerous specific aspects of studies contributing to the validity (and hence, quality). For example, internal validity is impacted by whether or not random assignment was used, the comparability of groups in quasi-experimental designs both initially and throughout the study, and the rates of attrition (to name just a few influences). Even more specifically, many fields of research have adapted—whether explicitly or implicitly—certain empirical practices that many researchers agree contribute to higher or lower quality of studying the phenomenon of interest (for a summary of three explicit sets of criteria, see Valentine, 2009).
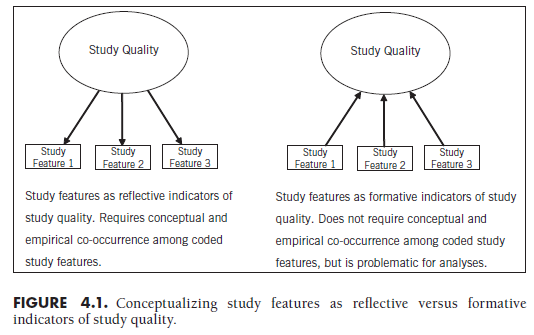
If you believe that these numerous features of studies reflect an underlying dimension of study quality, then you would expect these various features to co-occur across studies. For example, studies that have certain features reflecting internal validity should have other features reflecting internal validity, and studies with high internal validity should also have high external, construct, and statistical conclusion validity. Whether or not these cooccurrences exist in the particular collection of studies in your meta-analysis is both a conceptual and an empirical question. Conceptually, do you expect that the various features are reflections of a unidimensional quality construct in this area of study? Empirically, do you find substantial and consistent positive correlations among these features across the studies in your meta-analysis? If both of these conditions hold, then it may be reasonable to conceptualize an underlying (latent) construct of study quality (see left side of Figure 4.1). However, my impression is that in most fields, the conceptual argument is doubtful and the empirical evaluation is not made.
2. Usefulness of Moderation by Study Quality versus Specific Features
If you cannot provide conceptual and empirical support for an underlying “quality” construct leading to manifestations of different aspects of quality across studies, I believe that it becomes more difficult to describe some phenomenon of “quality.” Nevertheless, even if such a construct that produces consistent variation in features across studies does not exist, the collection of these features might still define something meaningful that could be termed “quality.” This situation is displayed on the right side of Figure 4.1. The difference between these two situations—one in which the features of the studies reflecting quality can be argued, conceptually and empirically, to co-occur (left) versus one in which the concept of quality is simply defined by these features—parallels the distinction between reflective versus formative indicators (see Figure 4.1 and, e.g., Edwards & Bagozzi, 2000; Howell, Breivik, & Wilcox, 2007; MacCallum & Browne, 1993). However, this approach would also suffer the same problems of formative measurement (e.g., Howell et al.,2007), including difficulties in defining the construct if some of the formative indicators differentially relate to presumed outcomes. In terms of metaanalytic moderator analyses (see Chapter 9), the problem arises when some study features might predict effect sizes at a magnitude—or even direction— differently than others. This situation will lead to a conceptual change in the definition of the “study quality” construct; more importantly, this situation obscures your ability to detect which specific features of the studies are related to variation in effect sizes across studies. I argue that it is typically more useful to understand the specific aspects of study quality that relate to the effect sizes found, rather than some broader, ill-defined construct of “study quality.”
3. Recommendations for Coding Study Quality
In sum, I have argued that (1) the conditions (conceptual unidimensionality and empirically observed substantial correlations) in which study features might be used as reflective indicators of a “study quality” construct are rare, and (2) attempting simply to combine the conceptually multidimensional and empirically uncorrelated (or modestly correlated) features as formative indicators of a “study quality” construct are problematic. This does not mean that I suggest not considering study quality. Instead, I suggest coding the various aspects of study quality that are potentially important within your field and evaluating these as multiple moderators of the effect sizes among your studies.
My recommendation to code, and later analyze (see Chapter 9), individual aspects of study quality means that you must make decisions about what aspects of study quality are important enough to code.3 These decisions can be guided by the same principles that guided your decision to code other potential moderators (see Section 4.1). Based on your knowledge of the area in which you are performing a meta-analysis, you should consider the research questions you are interested in and generally consider coding at least some of the aspects of study quality contributing to internal, external, and construct validity.4 My decision to organize coding around these aspects of validity follows Valentine (2009), and these possibilities are summarized in the bottom of Table 4.1.
3.1. Internal Validity
Internal validity refers to the extent to which the study design allows conclusions of causality from observed associations (e.g., association between group membership and outcome). The most important influence on internal validity is likely the study design, with experimental (i.e., random assignment) studies providing more internal validity than quasi-experimental studies (such as matched naturally occurring groups, regression continuity, and singlesubject designs; see Shadish et al., 2002). However, other study characteristics of studies might also impact internal validity. The degree to which condition is concealed to participants—also known as the “blinding” of participants to condition—impacts internal validity. For example, studies comparing a group receiving treatment (e.g., medication, psychotherapy) to a control group (e.g., placebo, treatment as usual) can have questionable internal validity if participants know which group they are in. Similarly, studies that are “double blind,” in that the researcher measuring the presumed outcome is unaware of participants’ group membership, are considered more internally valid in some areas of research. Finally, attrition—specifically selective and differential attrition between groups—can impact internal validity, especially in studies not using appropriate imputation technique (see Schafer & Graham, 2002).
3.2. External Validity
External validity refers to the extent to which the findings from a particular study can be generalized to different types of samples, conditions, or different ways of measuring the constructs of interest. However, attention to external validity focuses primarily on generalization to other types of samples/partici- pants. The most externally valid studies will randomly sample participants from a defined population (e.g., all registered voters in a region, all schoolchildren in the United States). In many, if not most, fields, this sort of random sampling is rare. So, it is important for you to determine what you consider a reasonably broad level of generalization in the research context of your metaanalysis, and code whether studies achieve this or focus on a more limited subpopulation (and likely the specific types of subpopulations).5 Fortunately, meta-analytic aggregation of individual studies with limited external validity can lead to conclusions that have greater external validity (see Chapter 2), provided that the studies within the meta-analysis collectively cover a wide range of relevant sample characteristics (see Section 4.1.2.a above on coding these characteristics).
3.3. Construct Validity
Construct validity refers to the degree to which the measures used in a study correspond to the theoretical construct the researchers intend to measure. The heading of “construct validity” is often used to refer to a wider range of measurement properties, including both the reliability and validity of the measure. I suggest coding the reliability of the measures comprising the two variables for potential effect size corrections (see Chapter 6). I do not support decisions to exclude studies with measures below a certain threshold reliability given that any choice of the threshold is arbitrary and because reliability scores reported in a study are imperfect parameter estimates (e.g., it is very plausible that two studies with identical sampling procedures from the same population, same methodology, and using the same measures could obtain slightly different estimates of internal consistency, perhaps with one at 0.78 and the other at 0.82 around an arbitrary 0.80 cutoff). It is more difficult to make such clear recommendations regarding the validity of the measures. Certainly, you should have a clear operational definition of the constructs of interest that can guide decisions about whether a study should or should not be included in your meta-analysis (see Chapter 3). Beyond this, it is possible to correct for imperfect validity (see Chapter 6), at least in situations where you have a good estimate of the correlation (i.e., validity coefficient) between the measure used in the study and some “gold standard” for the construct. Probably the safest approach is to treat this issue as an empirical question, and code relevant measurement characteristics (see Section 4.1.2.b) for use as potential moderators of study effect sizes.
3.4. Conclusions Regarding Coding Aspects of Quality
This consideration of study “quality” in terms of aspects of validity highlights the range of potential characteristics you can code for your meta-analysis. Given this range, I have treated the issue of coding study “quality” similarly to that of coding study characteristics (see Section 4.1), and do not see these aspects of “quality” holding a greater value than any other study characteristics.
At the same time, you should be aware of the “garbage in, garbage out” criticism (see Chapter 2), and consider this critique in light of the goals and intended audience of your meta-analysis. If your goal is to inform policy or practice, and the intended audience consists primarily of individuals who want clear, defensible answers (e.g., policymakers), then I suggest that you use aspects of study quality primarily as inclusion/exclusion criteria (see Chapter 3) in selecting studies (assuming that enough studies meet these inclusion criteria so as to provide a reasonably precise effect size estimate). In contrast, if your goal is to inform understanding of a phenomenon, and the intended audience is primarily individuals comfortable with nuanced, qualified conclusions (e.g., scientists), then I suggest coding these aspects of study quality for analysis as potential moderators of effect sizes (see Chapter 9). Perhaps a middle ground between these two recommendations is to code and evaluate moderation by various aspects of study quality, but to base policy or practice recommendations on results from higher-quality studies when these aspects are found to moderate effect sizes. Regardless of how these aspects of study quality are used (i.e., as inclusion/exclusion criteria versus coded moderators), I believe that a focus on specific aspects of study qualities is preferable to a single code intended to represent an overall “quality” construct.
Source: Card Noel A. (2015), Applied Meta-Analysis for Social Science Research, The Guilford Press; Annotated edition.
25 Aug 2021
25 Aug 2021
25 Aug 2021
25 Aug 2021
25 Aug 2021
25 Aug 2021