Because a research design is supposed to represent a logical set of statements, you also can judge the quality of any given design according to certain logical tests. Concepts that have been offered for these tests include trustworthiness, credibility, confirmability, and data dependability (U.S. Government Accountability Office, 1990).
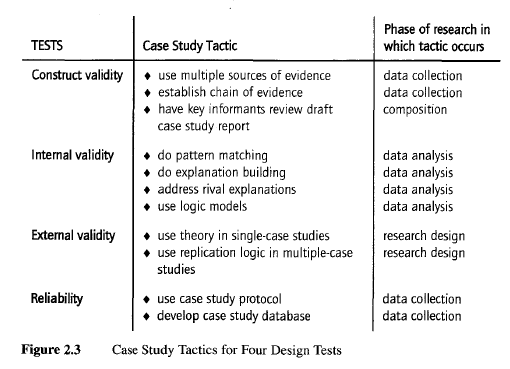
Four tests, however, have been commonly used to establish the quality of any empirical social research. Because case studies are one form of such research, the four tests also are relevant to case studies. An important innovation of this book is the identification of several tactics for dealing with these four tests when doing case studies. Figure 2.3 lists the four widely used tests and the recommended case study tactics, as well as a cross-reference to the phase of research when the tactic is to be used. (Each tactic is described in detail in the referenced chapter of this book.)
Because the four tests are common to all social science methods, the tests have been summarized in numerous textbooks (see L. Kidder & Judd, 1986, pp. 26-29):
- Construct validity: identifying correct operational measures for the concepts being studied
- Internal validity (for explanatory or causal studies only and not for descriptive or exploratory studies): seeking to establish a causal relationship, whereby certain conditions are believed to lead to other conditions, as distinguished from spurious relationships
- External validity: defining the domain to which a study’s findings can be generalized
- Reliability: demonstrating that the operations of a study—such as the data collection procedures—can be repeated, with the same results
Each item on this list deserves explicit attention. For case studies, an important revelation is that the several tactics to be used in dealing with these tests should be applied throughout the subsequent conduct of the case study, not just at its beginning. Thus, the “design work” for case studies may actually continue beyond the initial design plans.
1. Construct Validity
This first test is especially challenging in case study research. People who have been critical of case studies often point to the fact that a case study investigator fails to develop a sufficiently operational set of measures and that “subjective” judgments are used to collect the data.3 Take an example such as studying “neighborhood change”—a common case study topic (e.g., Bradshaw, 1999; Keating & Krumholz, 1999).
Over the years, concerns have arisen over how certain urban neighborhoods have changed their character. Any number of case studies has examined the types of changes and their consequences. However, without any prior specification of the significant, operational events that constitute “change,” a reader cannot tell whether the claimed changes in a case study genuinely reflect the events in a neighborhood or whether they happen to be based on an investigator’s impressions only.
Neighborhood change can cover a wide variety of phenomena: racial turnover, housing deterioration and abandonment, changes in the pattern of urban services, shifts in a neighborhood’s economic institutions, or the turnover from low- to middle-income residents in revitalizing neighborhoods. The choice of whether to aggregate blocks, census tracts, or larger areas also can produce different results (Hipp, 2007).
To meet the test of construct validity, an investigator must be sure to cover two steps:
- define neighborhood change in terms of specific concepts (and relate them to the original objectives of the study) and
- identify operational measures that match the concepts (preferably citing published studies that make the same matches).
For example, suppose you satisfy the first step by stating that you plan to study neighborhood change by focusing on trends in neighborhood crime. The second step now demands that you select a specific measure, such as police- reported crime (which happens to be the standard measure used in the FBI Uniform Crime Reports) as your measure of crime. The literature will indicate certain known shortcomings in this measure, mainly that unknown proportions of crimes are not reported to the police. You will then need to discuss how the shortcomings nevertheless will not bias your study of neighborhood crime and hence neighborhood change.
As Figure 2.3 shows, three tactics are available to increase construct validity when doing case studies. The first is the use of multiple sources of evidence, in a manner encouraging convergent lines of inquiry, and this tactic is relevant during data collection (see Chapter 4). A second tactic is to establish a chain of evidence, also relevant during data collection (also Chapter 4). The third tactic is to have the draft case study report reviewed by key informants (a procedure described further in Chapter 6).
2. Internal Validity
This second test has been given the greatest attention in experimental and quasi-experimental research (see Campbell & Stanley, 1966; Cook & Campbell, 1979). Numerous “threats” to validity have been identified, mainly dealing with spurious effects. However, because so many textbooks already cover this topic, only two points need to be made here.
First, internal validity is mainly a concern for explanatory case studies, when an investigator is trying to explain how and why event x led to event y. If the investigator incorrectly concludes that there is a causal relationship between x and y without knowing that some third factor—z,—may actually have caused y, the research design has failed to deal with some threat to internal validity. Note that this logic is inapplicable to descriptive or exploratory studies (whether the studies are case studies, surveys, or experiments), which are not concerned with this kind of causal situation.
Second, the concern over internal validity, for case study research, extends to the broader problem of making inferences. Basically, a case study involves an inference every time an event cannot be directly observed. An investigator will “infer” that a particular event resulted from some earlier occurrence, based on interview and documentary evidence collected as part of the case study. Is the inference correct? Have all the rival explanations and possibilities been considered? Is the evidence convergent? Does it appear to be airtight? A research design that has anticipated these questions has begun to deal with the overall problem of making inferences and therefore the specific problem of internal validity.
However, the specific tactics for achieving this result are difficult to identify. This is especially true in doing case studies. As one set of suggestions, Figure 2.3 shows that the analytic tactic of pattern matching, described further in Chapter 5, is one way of addressing internal validity. Three other analytic tactics, explanation building, addressing rival explanations, and using logic models, also are described in Chapter 5.
3. External Validity
The third test deals with the problem of knowing whether a study’s findings are generalizable beyond the immediate case study. In the simplest example, if a study of neighborhood change focused on one neighborhood, are the results applicable to another neighborhood? The external validity problem has been a major barrier in doing case studies. Critics typically state that single cases offer a poor basis for generalizing. However, such critics are implicitly contrasting the situation to survey research, in which a sample is intended to generalize to a larger universe. This analogy to samples and universes is incorrect when dealing with case studies. Survey research relies on statistical generalization, whereas case studies (as with experiments) rely on analytic generalization. In analytical generalization, the investigator is striving to generalize a particular set of results to some broader theory (see three examples in BOX 6).
For example, the theory of neighborhood change that led to a case study in the first place is the same theory that will help to identify the other cases to which the results are generalizable. If a study had focused on population transition in an urban neighborhood (e.g., Flippen, 2001), the procedure for selecting a neighborhood for study would have begun with identifying a neighborhood within which the hypothesized transitions were occurring. Theories about transition would then be the domain to which the results could later be generalized.
BOX 6
How Case Studies Can Be Generalized to Theory: Three Examples
6A. The Origins of Social Class Theory
The first example is about the uncovering and labeling of a social class structure based on a case study of a typical American city, Yankee City (Warner & Lunt, 1941). This classic case study in sociology made a critical contribution to social stratification theory and an understanding of social differences among “upper,” “upper- middle,” “middle-middle,” “upper-lower,” and “lower” classes.
6B. Contributions to Urban Planning Theory
The second example is Jane Jacobs and her famous book, The Death and Life of Great American Cities (1961). The book is based mostly on experiences from a single case, New York City. However, the chapter topics, rather than reflecting the single experiences of New York, cover broader theoretical issues in urban planning, such as the role of sidewalks, the role of neighborhood parks, the need for primary mixed uses, the need for small blocks, and the processes of slumming and unslumming. In the aggregate, these issues in fact represent Jacobs’s building of a theory of urban planning.
Jacobs’s book created heated controversy in the planning profession. As a partial result, new empirical inquiries were made in other locales, to examine one or another facet of her rich and provocative ideas. Her theory, in essence, became the vehicle for examining other cases, and the theory still stands as a significant contribution to the field of urban planning.
6C. A More Contemporary Example
A third example covers a 5-year ethnographic study of a single neighborhood at the edge of Chicago (Carr, 2003). The study shows how the neighborhood successfully thwarted undesirable youth-related crime. The experience, in the author’s view, challenged existing theories claiming that strong social ties are crucial to effective neighborhood control. Instead, the author offers newer theories of informal social control that he believes may be especially pertinent to youth crime prevention in contemporary suburban neighborhoods.
The generalization is not automatic, however. A theory must be tested by replicating the findings in a second or even a third neighborhood, where the theory has specified that the same results should occur. Once such direct replications have been made, the results might be accepted as providing strong support for the theory, even though further replications had not been performed. This replication logic is the same that underlies the use of experiments (and allows scientists to cumulate knowledge across experiments). The logic will be discussed further in this chapter in the section on multiple-case designs.
4. Reliability
Most people are probably already familiar with this final test. The objective is to be sure that, if a later investigator followed the same procedures as described by an earlier investigator and conducted the same case study all over again, the later investigator should arrive at the same findings and conclusions. (Note that the emphasis is on doing the same case over again, not on “replicating” the results of one case by doing another case study.) The goal of reliability is to minimize the errors and biases in a study.
One prerequisite for allowing this other investigator to repeat an earlier case study is the need to document the procedures followed in the earlier case. Without such documentation, you could not even repeat your own work (which is another way of dealing with reliability). In the past, case study research procedures have been poorly documented, making external reviewers suspicious of the reliability of the case study method.4 Figure 2.3 indicates two specific tactics to overcome these shortcomings—the use of a case study protocol to deal with the documentation problem in detail (discussed in Chapter 3) and the development of a case study database (discussed in Chapter 4).
The general way of approaching the reliability problem is to make as many steps as operational as possible and to conduct research as if someone were always looking over your shoulder. Accountants and bookkeepers always are aware that any calculations must be capable of being audited. In this sense, an auditor also is performing a reliability check and must be able to produce the same results if the same procedures are followed. A good guideline for doing case studies is therefore to conduct the research so that an auditor could in principle repeat the procedures and arrive at the same results.
Source: Yin K Robert (2008), Case Study Research Designs and Methods, SAGE Publications, Inc; 4th edition.
13 Aug 2021
13 Aug 2021
13 Aug 2021
13 Aug 2021
13 Aug 2021
13 Aug 2021