Based on classical test theory (Lord and Novick 1968), when an unobservable variable causes changes in its indicators, the specification of these indicators is reflective (For- nell and Bookstein 1982) or effect indicators (Bollen and Lennox 1991). By far, this is the most common type of measurement model in which the direction of influence flows from the unobserved construct to its indicators (MacKenzie et al. 2005). With this type of measurement model, the unobserved construct is itself responsible for explain- ing the variation in its indicators. Thus, all indicators should be relatively correlated because each indicator is a reflection or manifestation of the effects of the unobserved, or latent, construct. The assessment of reliability, unidimensionality, discriminant valid- ity, and convergent validity are all meaningful tests with reflective indicators. Addition- ally, reflective indicators are assumed to be interchangeable because they all represent aspects of the same conceptual domain (i.e., the unobservable construct; MacKenzie et al. 2005). Lastly, in specifying a model with reflective indicators, the error terms in the model are associated with each individual indicator rather than with the latent construct.
Alternatively, measurement models specified such that the direction of influence flows from the indicators to the unobservable construct are said to be comprised of formative or causal indicators (Bollen and Lennox 1991). With this type of measurement model, the underlying assumptions differ dramatically from the assumptions of a measurement model specified with reflective indicators. In fact, a measurement model with formative indicators involves the construction of an index rather than a scale. The indicators in a formative model are meant to contain the full meaning of the unobservable construct. In essence, the measures or indicators define and encompass the meaning of the latent construct.
Since formative indicators do not derive their meaning from the unobservable construct but instead define the unobservable construct, formative measures are not required to be positively correlated with each other. Thus, it would be perfectly acceptable for forma- tive indicators of an unobservable construct to be uncorrelated or even negatively cor- related with another. Nunnally and Bernstein (1994) note that two formative indicators can be negatively correlated and still serve as meaningful indicators of an unobservable construct. Thus, it is not necessarily the case that a set of formative indicators has a similar theme or content (Jarvis et al. 2003). Unlike reflective indicators, each formative indicator describes a part of the unobserved construct. Thus, formative indicators are not interchangeable, and dropping a formative indicator from a measurement model specifi- cation can result in a change in the definition of an unobservable construct. In fact, Bollen and Lennox (1991) state that “omitting an indicator is omitting a part of the construct” (p. 308). This emphasizes why the process of defining a construct with a measurement model composed of formative indicators is such an important process; by doing so, the researcher is actually describing and specifying what dimensions are forming the latent construct.
Because the underlying assumptions of a measurement model specified by formative indica- tors require no correlation among indicators, traditional procedures to assess internal consist- ency/reliability and construct validity are not appropriate. Bagozzi (1994) notes “reliability in the internal consistency sense and construct validity in terms of convergent and discrimi- nant validity are not meaningful when indexes are formed as a linear sum of measurements” (p. 333). Similarly, Bollen and Lennox (1991) state that since “causal indicators are not invali- dated by low internal consistency . . . to assess validity we need to examine other variables that are effects of the latent construct” (p. 312).
Though traditional validity concerns are not relevant for formative indicators, Diaman- topoulos and Winklhofer (2001) detail four areas of concern with formative indicators that must be addressed. The first one is content specification. This concern is based around the idea that you have fully specified all the dimensions that will “form” this construct. The next area is indicator specification. This concern details that you have included enough indicators or items in your model to fully capture the particular aspect of the construct. Next is indicator collinearity: multicollinearity between indicators is problematic with formative indicators. Excessive collinearity among indicators makes it difficult to separate the distinct influence of indicators on the unobserved construct. The last concern is exter- nal validity. A formative indicator model should have the ability to extend into multiple contexts.
The last distinction between formative and reflective indicators relates to the specification of error terms. In a reflective measurement model, error terms are associated with each indi- cator. A formative measurement model, however, must by definition represent error on the construct level. Thus, error must be assessed for the set of indicators (i.e., the index) rather than on the individual indicator level.This construct level error evaluation is meant to capture the missing facets or causes of the construct (Diamantopoulos 2006). Figure 4.43 contains some examples of formative models.
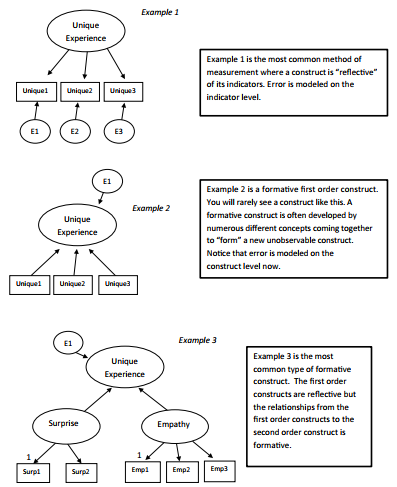
Figure 4.43a Examples of Acceptable and Unacceptable Second Order Models
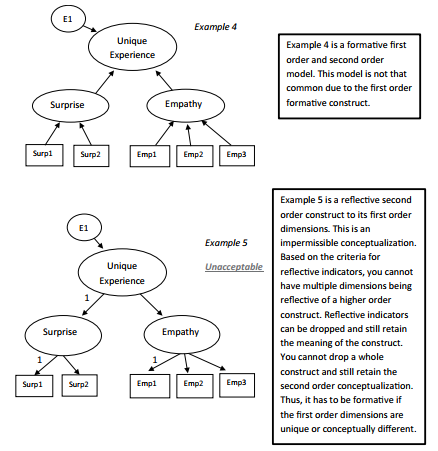
Figure 4.43b Examples of Acceptable and Unacceptable Second Order Models (Continued)
Source: Thakkar, J.J. (2020). “Procedural Steps in Structural Equation Modelling”. In: Structural Equation Modelling. Studies in Systems, Decision and Control, vol 285. Springer, Singapore.
27 Mar 2023
14 Sep 2022
27 Mar 2023
28 Mar 2023
31 Mar 2023
27 Mar 2023