1. Generate and replace
This chapter shows the basics of creating and modifying variables in Stata. We saw how to work with the Data Editor in [GSW] 6 Using the Data Editor—this chapter shows how we would do this from the Command window. The two primary commands used for this are
- generate for creating new variables. It has a minimum abbreviation of g.
- replace for replacing the values of an existing variable. It may not be abbreviated because it alters existing data and hence can be considered dangerous.
The most basic form for creating new variables is generate newvar = exp, where exp is any kind of expression. Of course, both generate and replace can be used with if and in qualifiers. An expression is a formula made up of constants, existing variables, operators, and functions. Some examples of expressions (using variables from auto.dta) would be 2 + price, weight~2 or sqrt(gear_ratio).
The operators defined in Stata are given in the table below:
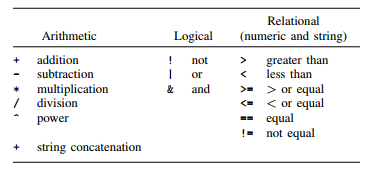
Stata has many mathematical, statistical, string, date, time-series, and programming functions. See help functions for the basics, and see the Stata Functions Reference Manual for a complete list and full details of all the built-in functions.
You can use menus and dialogs to create new variables and modify existing variables by selecting menu items from the Data > Create or change data menu. This feature can be handy for finding functions quickly. However, we will use the Command window for the examples in this chapter because we would like to illustrate simple usage and some pitfalls.
Stata has some utility commands for creating new variables:
- The egen command is useful for working across groups of variables or within groups of observations. See [D] egen for more information.
- The encode command turns categorical string variables into encoded numeric variables, while its counterpart decode reverses this operation. See [D] encode for more information.
- The destring command turns string variables that should be numeric, such as numbers with currency symbols, into numbers. To go from numbers to strings, the tostring command is useful. See [D] destring for more information.
We will focus our efforts on generate and replace.
2. Generate
There are some details you should know about the generate command:
- The basic form of the generate command is generate newvar = exp, where newvar is a new variable name and exp is any valid expression. You will get an error message if you try to generate a variable that already exists.
- An algebraic calculation using a missing value yields a missing value, as does division by zero, the square root of a negative number, or any other computation which is impossible.
- If missing values are generated, the number of missing values in newvar is always reported. If Stata says nothing about missing values, then no missing values were generated.
- You can use generate to set the storage type of the new variable as it is generated. You might want to create an indicator (0/1) variable as a byte, for example, because it saves 3 bytes per observation over using the default storage type of float.
Below are some examples of creating new variables from the afewcarslab dataset, which we created in Labeling values of variables in [GSW] 9 Labeling data. (To work along, start by opening the automobile dataset with sysuse auto. We are using a smaller dataset to make shorter listings.) The last example shows a way to generate an indicator variable for cars weighing more than 3,000 pounds. Logical expressions in Stata result in 1 for “true” and 0 for “false”. The if qualifier is used to ensure that the computations are done only for observations where weight is not missing.

3. Replace
Whereas generate is used to create new variables, replace is the command used for existing variables. Stata uses two different commands to prevent you from accidentally modifying your data. The replace command cannot be abbreviated. Stata generally requires you to spell out completely any command that can alter your existing data.

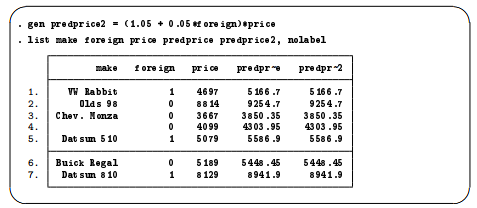
Suppose that you want to create a new variable, predprice, which will be the predicted price of the cars in the following year. You estimate that domestic cars will increase in price by 5% and foreign cars, by 10%.
One way to create the variable would be to first use generate to compute the predicted domestic car prices. Then use replace to change the missing values for the foreign cars to their proper values.

Of course, because foreign is an indicator variable, we could generate the predicted variable with one command:
4. generate with string variables
Stata is smart. When you generate a variable and the expression evaluates to a string, Stata creates a string variable with a storage type as long as necessary, and no longer than that. where is a strl in the following example:

Stata has some useful tools for working with string variables. Here we split the make variable into make and model and then create a variable that has the model together with where the model was manufactured:

There are a few things to note about how these commands work:
- ustrpos(si , s2) produces an integer equal to the first character in the string s1 at which the string s2 is found or 0 if it is not found. In this example, ustrpos(make,” “) finds the position of the first space in each observation of make.
- usubstr(s, start, len) produces a string of length len characters, beginning at character start of string s. If c1 = ., the result is the string from character start to the end of string s.
- Putting 1 and 2 together: usubstr(s,ustrpos(s,” “) + 1,.) will always give the string with its first word removed. Because make contains both the make and the model of each car, and make never contains a space in this dataset, we have found each car’s model.
- The operator “+”, when applied to string variables, will concatenate the strings (that is, join them together). The expression “this” + “that” results in the string “thisthat”. When the variable modelwhere was generated, a space (” “) was added between the two strings.
- The missing value for a string is nothing special—it is simply the empty string “”. Thus the value of modelwhere for the car with no make or model is ” D” (note the leading space).
If your strings might contain Unicode characters, use the Unicode versions of the string functions, as shown above. See [U] 12.4.2 Handling Unicode strings.
Source: STATA (2021), Getting Started with Stata for Windows, Stata Press Publication.
3 Oct 2022
23 Oct 2019
26 Sep 2022
3 Oct 2022
30 Sep 2022
30 Sep 2022