An effective information system provides users with accurate, timely, and relevant information. Accurate information is free of errors. Information is timely when it is available to decision makers when it is needed. Information is relevant when it is useful and appropriate for the types of work and decisions that require it.
You might be surprised to learn that many businesses don’t have timely, accurate, or relevant information because the data in their information systems have been poorly organized and maintained. That’s why data management is so essential. To understand the problem, let’s look at how information systems arrange data in computer files and traditional methods of file management.
1. File Organization Terms and Concepts
A computer system organizes data in a hierarchy that starts with bits and bytes and progresses to fields, records, files, and databases (see Figure 6.1). A bit represents the smallest unit of data a computer can handle. A group of bits, called a byte, represents a single character, which can be a letter, a number, or another symbol. A grouping of characters into a word, a group of words, or a complete number (such as a person’s name or age) is called a field. A group of related fields, such as the student’s name, the course taken, the date, and the grade, comprises a record; a group of records of the same type is called a file.
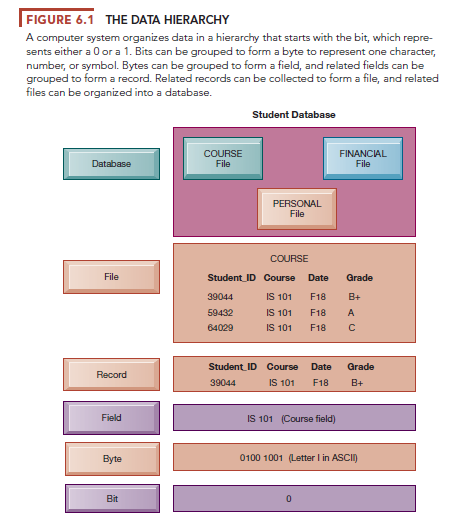
For example, the records in Figure 6.1 could constitute a student course file. A group of related files makes up a database. The student course file illustrated in Figure 6.1 could be grouped with files on students’ personal histories and financial backgrounds to create a student database.
A record describes an entity. An entity is a person, place, thing, or event on which we store and maintain information. Each characteristic or quality describing a particular entity is called an attribute. For example, Student_ID, Course, Date, and Grade are attributes of the entity COURSE. The specific values that these attributes can have are found in the fields of the record describing the entity COURSE.
2. Problems with the Traditional File Environment
In most organizations, systems tended to grow independently without a companywide plan. Accounting, finance, manufacturing, human resources, and sales and marketing all developed their own systems and data files. Figure 6.2 illustrates the traditional approach to information processing.

Each application, of course, required its own files and its own computer program to operate. For example, the human resources functional area might have a personnel master file, a payroll file, a medical insurance file, a pension file, a mailing list file, and so forth, until tens, perhaps hundreds, of files and programs existed. In the company as a whole, this process led to multiple master files created, maintained, and operated by separate divisions or departments. As this process goes on for 5 or 10 years, the organization is saddled with hundreds of programs and applications that are very difficult to maintain and manage. The resulting problems are data redundancy and inconsistency, program-data dependence, inflexibility, poor data security, and an inability to share data among applications.
2.1. Data Redundancy and Inconsistency
Data redundancy is the presence of duplicate data in multiple data files so that the same data are stored in more than one place or location. Data redundancy occurs when different groups in an organization independently collect the same piece of data and store it independently of each other. Data redundancy wastes storage resources and also leads to data inconsistency, where the same attribute may have different values. For example, in instances of the entity COURSE illustrated in Figure 6.1, the Date may be updated in some systems but not in others. The same attribute, Student_ID, might also have different names in different systems throughout the organization. Some systems might use Student_ID and others might use ID, for example.
Additional confusion can result from using different coding systems to represent values for an attribute. For instance, the sales, inventory, and manufacturing systems of a clothing retailer might use different codes to represent clothing size.
One system might represent clothing size as “extra large,” whereas another might use the code “XL” for the same purpose. The resulting confusion would make it difficult for companies to create customer relationship management, supply chain management, or enterprise systems that integrate data from different sources.
2.2. Program-Data Dependence
Program-data dependence refers to the coupling of data stored in files and the specific programs required to update and maintain those files such that changes in programs require changes to the data. Every traditional computer program has to describe the location and nature of the data with which it works. In a traditional file environment, any change in a software program could require a change in the data accessed by that program. One program might be modified from a five-digit to a nine-digit ZIP code. If the original data file were changed from five-digit to nine-digit ZIP codes, then other programs that required the five-digit ZIP code would no longer work properly. Such changes could cost millions of dollars to implement properly.
2.3. Lack of Flexibility
A traditional file system can deliver routine scheduled reports after extensive programming efforts, but it cannot deliver ad hoc reports or respond to unanticipated information requirements in a timely fashion. The information required by ad hoc requests is somewhere in the system but may be too expensive to retrieve. Several programmers might have to work for weeks to put together the required data items in a new file.
2.4. Poor Security
Because there is little control or management of data, access to and dissemination of information may be out of control. Management might have no way of knowing who is accessing or even making changes to the organization’s data.
2.5. Lack of Data Sharing and Availability
Because pieces of information in different files and different parts of the organization cannot be related to one another, it is virtually impossible for information to be shared or accessed in a timely manner. Information cannot flow freely across different functional areas or different parts of the organization. If users find different values for the same piece of information in two different systems, they may not want to use these systems because they cannot trust the accuracy of their data.
Source: Laudon Kenneth C., Laudon Jane Price (2020), Management Information Systems: Managing the Digital Firm, Pearson; 16th edition.
Thanks , I have recently been searching for info about this subject for a long time and yours is the best I have found out till now. But, what concerning the bottom line? Are you certain concerning the source?
As a Newbie, I am always searching online for articles that can aid me. Thank you