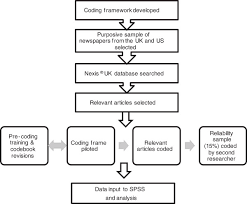
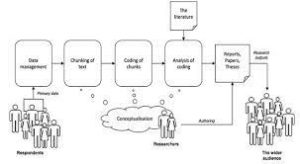
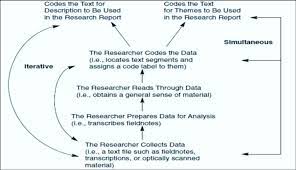
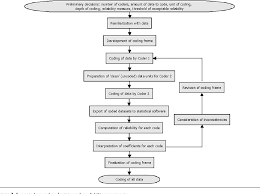
Preparing for Data Analysis in Content Analysis
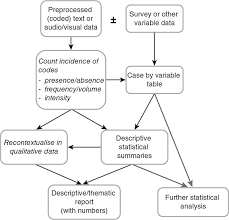
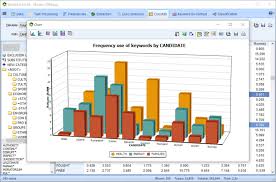
The basic analytic task in content analysis is to count the occurrence of codes, whether all occurrences of a given category (for example, all occurrences of Stars and Stripes articles that portray a negative image of the military) or only certain subcategories of occurrences (for example, Separate counts of such articles in the Pacific