We can combine Stata datasets in two general ways: append a second dataset that contains additional observations, or merge with other datasets that contain new variables or values. For example, file lakewinl.dta contains the ice-out dates for New Hampshire’s largest lake, recorded by local observers over 121 years from 1887 through 2007.

In 2007, Lake Winnipesaukee ice out occurred on April 23, the 113th day of the year.
File lakewin2.dta contains newer data from 2008 through 2012. It has the same variables and format, so we can combine the update in lakewin2.dta with the older information in lakewinl.dta, using the append command.
. use C:\data\lakewin2.dta
(Lake Winnipesaukee ice oul 2008-2012)
. describe

In this example, both datasets contained the same variables, although that is not necessary for append to work. Variables that exist only in one of the appended datasets are assigned missing values for observations from the other dataset, when the two are combined.
append might be compared to lengthening a sheet of paper (that is, the dataset in memory) by taping a second sheet with new observations (rows) to its bottom. merge, in its simplest form, corresponds to widening our sheet of paper by taping a second sheet to its right side, thereby adding new variables (columns).
File lakesun.dta contains ice out dates for New Hampshire’s second-largest lake over the years 1869 through 2012. Although the Lake Sunapee (lakesun.dta) and Lake Winnipesaukee (lakewin3.dta) records come from different sources, both form yearly series that could easily be combined into one dataset. We do this with the merge 1:1 year command.
. use C:\data\lakesun.dta

Both datasets were already sorted by year; if they were not, we would have to sort year before merging. The merge results tell us that 126 years were present in both the “master” dataset (the data currently in memory—lakesun.dta in this example) and the “using” dataset (lakewin3.dta). A further 18 years (1869 to 1886) existed only in lakesun.dta, so the Lake Winnipesaukee variables will have missing values in those years. merge commands create a variable named merge that records whether the observation came from the master data only ( merge = 1), the using data only (merge = 2), or from both (merge = 3). It is an important step to review merge values carefully after each merge operation, making sure things turned out as planned. Before performing another merge operation, we must drop or rename merge.
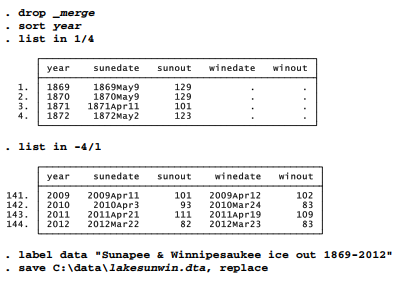
In this example, we simply used merge to add new variables to our data, matching observations on year. By default, whenever the same variables are found in both datasets, those of the master data are retained and those of the using data ignored. The merge command has several options, however, that override this default. A command of the following form would allow any missing values in the master data to be replaced by corresponding nonmissing values found in the using data (here, newdata.dta):
. merge 1:1 year using newdata.dta, update
Or, a command such as the following causes any values from the master data to be replaced by nonmissing values from the using data, if the latter are different:
. merge 1:1 year using newdata, update replace
All of these examples show simple 1-to-1 merging. Also possible are 1-to-many (1:m), many- to-1 (m:1) or many-to-many (m:m) operations. Type help merge for details, and see the Data Management manual for further examples. Merging and appending data can be accomplished through Data > Combine datasets menus, as well.
Source: Hamilton Lawrence C. (2012), Statistics with STATA: Version 12, Cengage Learning; 8th edition.
3 Oct 2022
29 Sep 2022
28 Sep 2022
30 Sep 2022
23 Sep 2022
30 Sep 2022