Letting μ1 denote the mean of population 1 and μ2 denote the mean of population 2, we will focus on inferences about the difference between the means: μ1 – μ2. To make an inference about this difference, we select a simple random sample of n1 units from population 1 and a second simple random sample of n2 units from population 2. The two samples, taken separately and independently, are referred to as independent simple random samples.
In this section, we assume that information is available such that the two population standard deviations, σ1 and σ2, can be assumed known prior to collecting the samples. We refer to this situation as the σ1 and σ2 known case. In the following example we show how to compute a margin of error and develop an interval estimate of the difference between the two population means when σ1 and σ2 are known.
1. Interval Estimation of μ1 – μ2
Greystone Department Stores, Inc., operates two stores in Buffalo, New York: One is in the inner city and the other is in a suburban shopping center. The regional manager noticed that products that sell well in one store do not always sell well in the other. The manager believes this situation may be attributable to differences in customer demographics at the two locations. Customers may differ in age, education, income, and so on. Suppose the manager asks us to investigate the difference between the mean ages of the customers who shop at the two stores.
Let us define population 1 as all customers who shop at the inner-city store and population 2 as all customers who shop at the suburban store.

The difference between the two population means is μ1 – μ2.
To estimate μ1 – μ2, we will select a simple random sample of n1 customers from population 1 and a simple random sample of n2 customers from population 2. We then compute the two sample means.
x1 = sample mean age for the simple random sample of n1 inner-city customers
x2 = sample mean age for the simple random sample of n2 suburban customers
The point estimator of the difference between the two population means is the difference between the two sample means.
Figure 10.1 provides an overview of the process used to estimate the difference between two population means based on two independent simple random samples.

As with other point estimators, the point estimator xi — x2 has a standard error that describes the variation in the sampling distribution of the estimator. With two independent simple random samples, the standard error of xi— x2 is as follows:

If both populations have a normal distribution, or if the sample sizes are large enough that the central limit theorem enables us to conclude that the sampling distributions of xi and x2 can be approximated by a normal distribution, the sampling distribution of xi — x2 will have a normal distribution with mean given by μ2 — μ2.
In general, an interval estimate is given by a point estimate ± a margin of error. In the case of estimation of the difference between two population means, an interval estimate will take the following form:
![]()
With the sampling distribution of xi — x2 having a normal distribution, we can write the margin of error as follows:
![]()
Thus the interval estimate of the difference between two population means is as follows:

Let us return to the Greystone example. Based on data from previous customer demographic studies, the two population standard deviations are known with σ1 = 9 years and s2 = 10 years. The data collected from the two independent simple random samples of Greystone customers provided the following results.
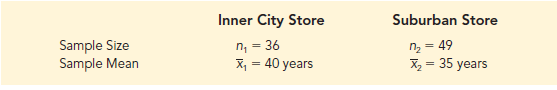
Using expression (10.1), we find that the point estimate of the difference between the mean ages of the two populations is X1 – X2 = 40 – 35 = 5 years. Thus, we estimate that the customers at the inner-city store have a mean age five years greater than the mean age of the suburban store customers. We can now use expression (10.4) to compute the margin of error and provide the interval estimate of Thus the interval estimate of the difference between two population means is as follows: μ1 – μ2. Using 95% confidence and za/2 = z.025 = 1.96, we have

Thus, the margin of error is 4.06 years and the 95% confidence interval estimate of the difference between the two population means is 5 – 4.06 = .94 years to 5 + 4.06 = 9.06 years.
2. Hypothesis Tests About μ2– μ2
Let us consider hypothesis tests about the difference between two population means. Using D0 to denote the hypothesized difference between μ1 and μ2, the three forms for a hypothesis test are as follows:

In many applications, D0 = 0. Using the two-tailed test as an example, when D0 = 0 the null hypothesis is H0: μ1 – m2 = 0. In this case, the null hypothesis is that m1 and m2 are equal. Rejection of H0 leads to the conclusion that Ha: μ1 – μ2 # 0 is true; that is, μ1 and μ2 are not equal.
The general steps for conducting hypothesis tests are still applicable here. We must choose a level of significance, compute the value of the test statistic, and find the p-value to determine whether the null hypothesis should be rejected. With two independent simple random samples, we showed that the point estimator X1 – X2 has a standard error sXi 2– given by expression (10.2) and, when the sample sizes are large enough, the distribution of X1 – X2 can be described by a normal distribution. In this case, the test statistic for the difference between two population means when σ1 and σ2 are known is as follows.

Let us demonstrate the use of this test statistic in the following hypothesis testing example.
As part of a study to evaluate differences in education quality between two training centers, a standardized examination is given to individuals who are trained at the centers. The difference between the mean examination scores is used to assess quality differences between the centers. The population means for the two centers are as follows.

We begin with the tentative assumption that no difference exists between the training quality provided at the two centers. Hence, in terms of the mean examination scores, the null hypothesis is that μi – μ2 = 0. If sample evidence leads to the rejection of this hypothesis, we will conclude that the mean examination scores differ for the two populations. This conclusion indicates a quality differential between the two centers and suggests that a follow-up study investigating the reason for the differential may be warranted. The null and alternative hypotheses for this two-tailed test are written as follows.

The standardized examination given previously in a variety of settings always resulted in an examination score standard deviation near 10 points. Thus, we will use this information to assume that the population standard deviations are known with σ1 = 10 and σ2 = 10. An a = .05 level of significance is specified for the study.
Independent simple random samples of n1 = 30 individuals from training center A and n2 = 40 individuals from training center B are taken. The respective sample means are x1 = 82 and x2 = 78. Do these data suggest a significant difference between the population means at the two training centers? To help answer this question, we compute the test statistic using equation (10.5).
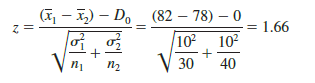
Next let us compute the p-value for this two-tailed test. Because the test statistic z is in the upper tail, we first compute the area under the curve to the right of z = 1.66. Using the standard normal distribution table, the area to the left of z = 1.66 is .9515. Thus, the area in the upper tail of the distribution is 1.0000 – .9515 = .0485. Because this test is a twotailed test, we must double the tail area: p-value = 2(.0485) = .0970. Following the usual rule to reject H0 if p-value < a, we see that the p-value of .0970 does not allow us to reject H0 at the .05 level of significance. The sample results do not provide sufficient evidence to conclude the training centers differ in quality.
In this chapter we will use the p-value approach to hypothesis testing. However, if you prefer, the test statistic and the critical value rejection rule may be used. With a = .05 and za/2 = z.025 = 1 96, the rejection rule employing the critical value approach would be reject H0 if z ≤ -1.96 or if z ≥ 1.96. With z = 1.66, we reach the same do not reject H0 conclusion.
In the preceding example, we demonstrated a two-tailed hypothesis test about the difference between two population means. Lower tail and upper tail tests can also be considered. These tests use the same test statistic as given in equation (10.5). The procedure for computing the p-value and the rejection rules for these one-tailed tests are the same as those for hypothesis tests involving a single population mean and single population proportion.
3. Practical Advice
In most applications of the interval estimation and hypothesis testing procedures presented in this section, random samples with n1 ≥ 30 and n2 ≥ 30 are adequate. In cases where either or both sample sizes are less than 30, the distributions of the populations become important considerations. In general, with smaller sample sizes, it is more important for the analyst to be satisfied that it is reasonable to assume that the distributions of the two populations are at least approximately normal.
Source: Anderson David R., Sweeney Dennis J., Williams Thomas A. (2019), Statistics for Business & Economics, Cengage Learning; 14th edition.
31 Aug 2021
30 Aug 2021
31 Aug 2021
30 Aug 2021
28 Aug 2021
31 Aug 2021