The web is the most popular Internet service. It’s a system with universally accepted standards for storing, retrieving, formatting, and displaying information by using a client/server architecture. Web pages are formatted using hypertext, embedded links that connect documents to one another and that also link pages to other objects, such as sound, video, or animation files. When you click a graphic and a video clip plays, you have clicked a hyperlink. A typical website is a collection of web pages linked to a home page.
1. Hypertext
Web pages are based on a standard Hypertext Markup Language (HTML), which formats documents and incorporates dynamic links to other documents and other objects stored in the same or remote computers (see Chapter 5). Web pages are accessible through the Internet because web browser software operating your computer can request web pages stored on an Internet host server by using the Hypertext Transfer Protocol (HTTP). HTTP is the communications standard that transfers pages on the web. For example, when you type a web address in your browser, such as http://www.sec.gov, your browser sends an HTTP request to the sec.gov server requesting the home page of sec.gov.
HTTP is the first set of letters at the start of every web address, followed by the domain name, which specifies the organization’s server computer that is storing the web page. Most companies have a domain name that is the same as or closely related to their official corporate name. The directory path and web page name are two more pieces of information within the web address that help the browser track down the requested page. Together, the address is called a uniform resource locator (URL). When typed into a browser, a URL tells the browser software exactly where to look for the information. For example, in the URL http://www.megacorp.com/content/features/082610.html, http names the protocol that displays web pages, www.megacorp.com is the domain name, content/features is the directory path that identifies where on the domain web server the page is stored, and 082610.html is the web page name and the name of the format it is in. (It is an HTML page.)
2. Web Servers
A web server is software for locating and managing stored web pages. It locates the web pages a user requests on the computer where they are stored and delivers the web pages to the user’s computer. Server applications usually run on dedicated computers, although they can all reside on a single computer in small organizations.
The leading web servers in use today are Microsoft Internet Information Services (IIS) and Apache HTTP Server. Apache is an open source product that is free of charge and can be downloaded from the web.
3. Searching for Information on the Web
No one knows for sure how many web pages there really are. The surface web is the part of the web that search engines visit and about which information is recorded. For instance, Google indexed an estimated 35 trillion pages in 2017, and this reflects a large portion of the publicly accessible web page population, estimated to be 60 trillion pages. But there is a deep web that contains an estimated 1 trillion additional pages, many of them proprietary (such as the pages of Wall Street Journal Online, which cannot be visited without a subscription or access code), or that are stored in protected corporate databases. Facebook, with web pages of text, photos, and media for more than 2 billion members, is a closed web, and its pages are not completely searchable by Google or other search engines. A small portion of the deep web called the dark web has been intentionally hidden from search engines, uses masked IP addresses, and is accessible only with a special web browser in order to preserve anonymity.
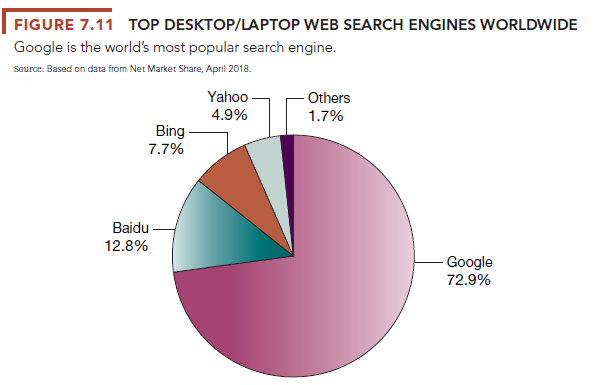
Search Engines Obviously, with so many web pages, finding specific ones that can help you or your business, nearly instantly, is an important problem. The question is, how can you find the one or two pages you really want and need out of billions of indexed web pages? Search engines attempt to solve the problem of finding useful information on the web nearly instantly and, arguably, they are the killer app of the Internet era. Today’s search engines can sift through HTML files; files of Microsoft Office applications; PDF files; and audio, video, and image files. There are hundreds of search engines in the world, but the vast majority of search results come from Google, Baidu, Yahoo, and Microsoft’s Bing (see Figure 7.11). While we typically think of Amazon as an online store, it is also a powerful product search engine.
Web search engines started out in the early 1990s as relatively simple software programs that roamed the nascent web, visiting pages and gathering information about the content of each page. The first search engines were simple keyword indexes of all the pages they visited, leaving users with lists of pages that may not have been truly relevant to their search.
In 1994, Stanford University computer science students David Filo and Jerry Yang created a hand-selected list of their favorite web pages and called it “Yet Another Hierarchical Officious Oracle,” or Yahoo. Yahoo was not initially a search engine but rather an edited selection of websites organized by categories the editors found useful. Currently, Yahoo relies on Microsoft’s Bing for search results.
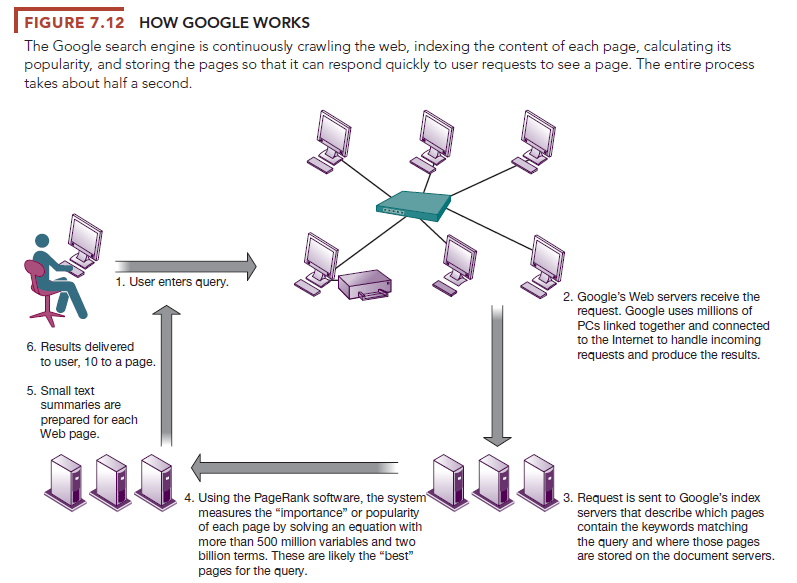
In 1998, Larry Page and Sergey Brin, two other Stanford computer science students, released their first version of Google. This search engine was different. Not only did it index each web page’s words but it also ranked search results based on the relevance of each page. Page patented the idea of a page ranking system (called PageRank System), which essentially measures the popularity of a web page by calculating the number of sites that link to that page as well as the number of pages to which it links. The premise is that popular web pages are more relevant to users. Brin contributed a unique web crawler program that indexed not only keywords on a page but also combinations of words (such as authors and the titles of their articles). These two ideas became the foundation for the Google search engine. Figure 7.12 illustrates how Google works.
Mobile Search Mobile search from smartphones and tablets makes up more than 50 percent of all searches and will expand rapidly in the next few years. Google, Amazon, and Yahoo have developed new search interfaces to make searching and shopping from smartphones more convenient. Google revised its search algorithm to favor sites that look good on smartphone screens. Although smartphones are widely used to shop, actual purchases typically take place on laptops or desktops, followed by tablets.
Semantic Search Another way for search engines to become more discriminating and helpful is to make search engines capable of understanding what we are really looking for. Called semantic search, the goal is to build a search engine that can really understand human language and behavior. Google and other search engine firms are attempting to refine search engine algorithms to capture more of what the user intended and the meaning of a search. Rather
than evaluate each word separately in a search, Google’s Hummingbird search algorithm tries to evaluate an entire sentence, focusing on the meaning behind the words. For instance, if your search is a long sentence like “Google annual report selected financial data 2018,” Hummingbird should be able to figure out that you really want Google’s parent company Alphabet’s SEC Form 10K report filed with the Securities and Exchange Commission in February 2018.
Google searches also take advantage of Knowledge Graph, an effort of the search algorithm to anticipate what you might want to know more about as you search on a topic. Results of the knowledge graph appear on the right of the screen on many search result pages and contain more information about the topic or person you are searching on. For example, if you search “Lake Tahoe,” the search engine will return basic facts about Tahoe (altitude, average temperature, and local fish), a map, and hotel accommodations. Google has made predictive search part of most search results. This part of the search algorithm guesses what you are looking for and suggests search terms as you type your search words.
Social Search One problem with Google and mechanical search engines is that they are so thorough. Enter a search for “ultra computers” and, in 0.2 seconds, you will receive over 300 million responses! Social search is an effort to provide fewer, more relevant, and trustworthy search results based on a person’s network of social contacts. In contrast to the top search engines that use a mathematical algorithm to find pages that satisfy your query, social search would highlight content that was created or touched by members of your social network.
Facebook Search is a social network search engine that responds to user search queries with information from the user’s social network of friends and connections. Facebook Search relies on the huge amount of data on Facebook that is, or can be, linked to individuals and organizations. You might use Facebook Search to search for Boston restaurants that your friends like or pictures of your friends before 2016.
Visual Search and the Visual Web Although search engines were originally designed to search text documents, the explosion of photos and videos on the Internet created a demand for searching and classifying these visual objects. Facial recognition software can create a digital version of a human face. Facebook has a tag suggest function to assist users in tagging their friends in photos. You can also search for people on Facebook by using their digital image to find and identify them. Facebook is now using artificial intelligence technology to make its facial recognition capabilities more accurate.
Searching photos, images, and video has become increasingly important as the web becomes more visual. The visual web refers to websites such as Pinterest, where pictures replace text documents, where users search pictures, and where pictures of products replace display ads for products. Pinterest is a social networking site that provides users (as well as brands) with an online board to which they can pin interesting pictures. Pinterest had 200 million active monthly users worldwide in 2018. Instagram is another example of the visual web. Instagram is a photo and video sharing site that allows users to take pictures, enhance them, and share them with friends on other social sites such as Facebook and Twitter. In 2018, Instagram had 800 million monthly active users.
Intelligent Agent Shopping Bots Chapter 11 describes the capabilities of software agents with built-in intelligence that can gather or filter information and perform other tasks to assist users. Shopping bots use intelligent agent software for searching the Internet for shopping information. Shopping bots such as MySimon or PriceGrabber, and travel search tools like Trivago, can help people interested in making a purchase or renting a vacation room filter and retrieve information according to criteria the users have established, and in some cases negotiate with vendors for price and delivery terms.
Search Engine Marketing Search engines have become major advertising platforms and shopping tools by offering what is now called search engine marketing. Searching for information is one of the web’s most popular activities; it is estimated that 242 million people in the United States will use search engines by 2019 and 215 million will use mobile search by that time. With this huge audience, search engines are the foundation for the most lucrative form of online marketing and advertising: search engine marketing. When users enter a search term on Google, Bing, Yahoo, or any of the other sites serviced by these search engines, they receive two types of listings: sponsored links, for which advertisers have paid to be listed (usually at the top of the search results page), and unsponsored, organic search results. In addition, advertisers can purchase small text boxes on the side of search results pages. The paid, sponsored advertisements are the fastest growing form of Internet advertising and are powerful new marketing tools that precisely match consumer interests with advertising messages at the right moment. Search engine marketing monetizes the value of the search process. In 2018, search engine marketing was expected to generate $42 billion, or 44.2 percent of digital ad spending, nearly half of all online advertising ($93 billion) (eMarketer, 2018). About 90 percent of Google’s revenue of $110 billion in 2017 came from online advertising, and 90 percent of that ad revenue came from search engine marketing (Alphabet, 2018).
Because search engine marketing is so effective (it has the highest clickthrough rate and the highest return on ad investment), companies seek to optimize their websites for search engine recognition. The better optimized the page is, the higher a ranking it will achieve in search engine result listings. Search engine optimization (SEO) is the process of improving the quality and volume of web traffic to a website by employing a series of techniques that help a website achieve a higher ranking with the major search engines when certain keywords and phrases are put into the search field. One technique is to make sure that the keywords used in the website description match the keywords likely to be used as search terms by prospective customers. For example, your website is more likely to be among the first ranked by search engines if it uses the keyword lighting rather than lamps if most prospective customers are searching for lighting. It is also advantageous to link your website to as many other websites as possible because search engines evaluate such links to determine the popularity of a web page and how it is linked to other content on the web.
Search engines can be gamed by scammers who create thousands of phony website pages and link them to a single retailer’s site in an attempt to fool Google’s search engine. Firms can also pay so-called link farms to link to their site. Google changed its search algorithm in 2012 to deal with this problem by examining the quality of links more carefully with the intent of down-ranking sites that have a suspicious pattern of sites linking to them.
In general, search engines have been very helpful to small businesses that cannot afford large marketing campaigns. Because shoppers are looking for a specific product or service when they use search engines, they are what marketers call hot prospects—people who are looking for information and often intending to buy. Moreover, search engines charge only for click-throughs to a site. Merchants do not have to pay for ads that don’t work, only for ads that receive a click. Consumers benefit from search engine marketing because ads for merchants appear only when consumers are looking for a specific product. Thus, search engine marketing saves consumers cognitive energy and reduces search costs (including the cost of transportation needed to search for products physically). One study estimated the global value of search to both merchants and consumers to be more than $800 billion, with about 65 percent of the benefit going to consumers in the form of lower search costs and lower prices (McKinsey & Company, 2011).
4. Sharing Information on the Web
Today’s websites don’t just contain static content—they enable people to collaborate, share information, and create new services and content online. Today’s web can support interactivity, real-time user control, social participation (sharing), and user-generated content. The technologies and services behind these features include cloud computing, software mashups and apps, blogs, RSS, wikis, and social networks. We have already described cloud computing, mash- ups, and apps in Chapter 5 and introduced social networks in Chapter 2.
A blog, the popular term for a weblog, is a personal website that typically contains a series of chronological entries (newest to oldest) by its author and links to related web pages. The blog may include a blogroll (a collection of links to other blogs) and trackbacks (a list of entries in other blogs that refer to a post on the first blog). Most blogs allow readers to post comments on the blog entries as well. The act of creating a blog is often referred to as blogging. Blogs can be hosted by a third-party service such as Blogger.com or TypePad.com, and blogging features have been incorporated into social networks such as Facebook and collaboration platforms such as IBM Notes. WordPress is a leading open source blogging tool and content management system. Microblogging, used in Twitter or other platforms with serious space or size constraints, is a type of blogging that features very small elements of content such as short sentences, individual images, or video links.
Blog pages are usually based on templates provided by the blogging service or software. Therefore, millions of people without HTML skills of any kind can post their own web pages and share content with others. The totality of blog- related websites is often referred to as the blogosphere. Although blogs have become popular personal publishing tools, they also have business uses (see Chapters 2 and 10).
If you’re an avid blog reader, you might use RSS to keep up with your favorite blogs without constantly checking them for updates. RSS, which stands for Really Simple Syndication or Rich Site Summary, pulls specified content from websites and feeds it automatically to users’ computers. RSS reader software gathers material from the websites or blogs that you tell it to scan and brings new information from those sites to you. RSS readers are available through websites such as Google and Yahoo, and they have been incorporated into the major web browsers and email programs.
Blogs allow visitors to add comments to the original content, but they do not allow visitors to change the original posted material. Wikis, in contrast, are collaborative websites on which visitors can add, delete, or modify content, including the work of previous authors. Wiki comes from the Hawaiian word for “quick.”
Wiki software typically provides a template that defines layout and elements common to all pages, displays user-editable software program code, and then renders the content into an HTML-based page for display in a web browser. Some wiki software allows only basic text formatting, whereas other tools allow the use of tables, images, or even interactive elements, such as polls or games.
Most wikis provide capabilities for monitoring the work of other users and correcting mistakes.
Because wikis make information sharing so easy, they have many business uses. The U.S. Department of Homeland Security’s National Cyber Security Center (NCSC) deployed a wiki to facilitate information sharing with other federal agencies on threats, attacks, and responses and as a repository for technical and standards information. Pixar Wiki is a collaborative community wiki for publicizing the work of Pixar Animation Studios. The wiki format allows anyone to create or edit an article about a Pixar film.
Social networking sites enable users to build communities of friends and professional colleagues. Members typically create a profile—a web page for posting photos, videos, audio files, and text—and then share these profiles with others on the service identified as their friends or contacts. Social networking sites are highly interactive, offer real-time user control, rely on user-generated content, and are broadly based on social participation and sharing of content and opinions. Leading social networking sites include Facebook, Twitter, and LinkedIn (for professional contacts).
Social networking has radically changed how people spend their time online; how people communicate and with whom; how business people stay in touch with customers, suppliers, and employees; how providers of goods and services learn about their customers; and how advertisers reach potential customers. The large social networking sites are also application development platforms where members can create and sell software applications to other members of the community. Facebook alone has more than 7 million apps and websites integrated with it, including applications for gaming, video sharing, and communicating with friends and family. We talk more about business applications of social networking in Chapters 2 and 10, and you can find social networking discussions in many other chapters of this book.
5. The Future Web
The future Internet is becoming visible. Its key features are more tools for individuals to make sense out of the trillions of pages on the Internet, or the millions of apps available for smartphones and a visual, even three-dimensional (3D) web where you can walk through pages in a 3D environment. (Review the discussion of semantic search and visual search earlier in this chapter.)
Even closer in time is a pervasive web that controls everything from a city’s traffic lights and water usage, to the lights in your living room, to your car’s rear view mirror, not to mention managing your calendar and appointments. This is referred to as the Internet of Things (IoT) and is based on billions of Internet-connected sensors throughout our physical world. Objects, animals, or people are provided with unique identifiers and the ability to transfer data over a network without requiring human-to-human or human-to-computer interaction. Firms such as General Electric, IBM, HP, and Oracle, and hundreds of smaller startups, are exploring how to build smart machines, factories, and cities through extensive use of remote sensors and fast cloud computing. We provide more detail on this topic in the following section.
The App Internet is another element in the future web. The growth of apps within the mobile platform is astounding. More than 80 percent of mobile minutes in the United States are generated through apps, as opposed to browsers. Apps give users direct access to content and are much faster than loading a browser and searching for content.
Other complementary trends leading toward a future web include more widespread use of cloud computing and software as a service (SaaS) business models, ubiquitous connectivity among mobile platforms and Internet access devices, and the transformation of the web from a network of separate siloed applications and content into a more seamless and interoperable whole.
Source: Laudon Kenneth C., Laudon Jane Price (2020), Management Information Systems: Managing the Digital Firm, Pearson; 16th edition.
It’s nearly impossible to find educated people on this topic, but you seem like you know what you’re
talking about! Thanks
Thanks for the good writeup. It in reality
used to be a amusement account it. Look complex to more introduced
agreeable from you! However, how could we be in contact?
I wanted to thank you for this great read!! I certainly enjoyed every
bit of it. I have got you book marked to look at new things you post…
Thanks for this post, I am a big fan of this site would like to continue updated.