Content analysis is a research tool used to determine the presence of certain words, themes, or concepts within some given qualitative data (i.e. text). Using content analysis, researchers can quantify and analyze the presence, meanings and relationships of such certain words, themes, or concepts. As an example, researchers can evaluate language used within a news article to search for bias or partiality. Researchers can then make inferences about the messages within the texts, the writer(s), the audience, and even the culture and time of surrounding the text.
Sources of data could be from interviews, open-ended questions, field research notes, conversations, or literally any occurrence of communicative language (such as books, essays, discussions, newspaper headlines, speeches, media, historical documents). A single study may analyze various forms of text in its analysis. To analyze the text using content analysis, the text must be coded, or broken down, into manageable code categories for analysis (i.e. “codes”). Once the text is coded into code categories, the codes can then be further categorized into “code categories” to summarize data even further.
Main contentsSee more from basic to advanced






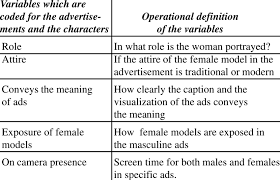







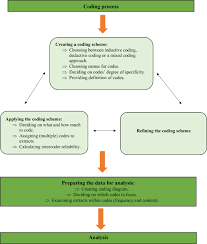



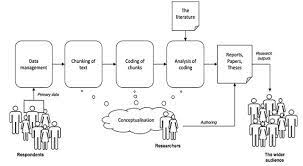

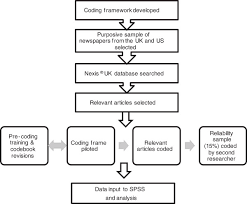
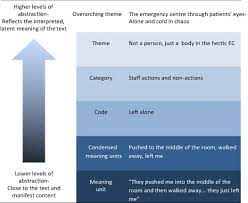
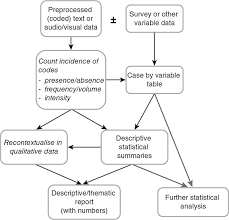
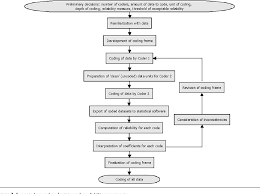
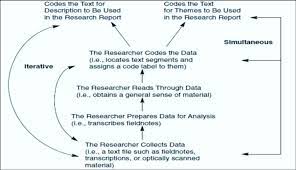
Quantitative content analysis highlights frequency counts and objective analysis of these coded frequencies. Additionally, quantitative content analysis begins with a framed hypothesis with coding decided on before the analysis begins. These coding categories are strictly relevant to the researcher’s hypothesis. Quantitative analysis also takes a deductive approach.
Siegfried Kracauer provides a critique of quantitative analysis, asserting that it oversimplifies complex communications in order to be more reliable. On the other hand, qualitative analysis deals with the intricacies of latent interpretations, whereas quantitative has a focus on manifest meanings. He also acknowledges an “overlap” of qualitative and quantitative content analysis. Patterns are looked at more closely in qualitative analysis, and based on the latent meanings that the researcher may find, the course of the research could be changed. It is inductive and begins with open research questions, as opposed to a hypothesis.
Three different definition of content analysis are provided below.
- Definition 1: “Any technique for making inferences by systematically and objectively identifying special characteristics of messages.” (from Holsti, 1968)
- Definition 2: “An interpretive and naturalistic approach. It is both observational and narrative in nature and relies less on the experimental elements normally associated with scientific research (reliability, validity and generalizability) (from Ethnography, Observational Research, and Narrative Inquiry, 1994-2012).
- Definition 3: “A research technique for the objective, systematic and quantitative description of the manifest content of communication.” (from Berelson, 1952)
Uses of Content Analysis
- Identify the intentions, focus or communication trends of an individual, group or institution
- Describe attitudinal and behavioral responses to communications
- Determine psychological or emotional state of persons or groups
- Reveal international differences in communication content
- Reveal patterns in communication content
- Pre-test and improve an intervention or survey prior to launch
- Analyze focus group interviews and open-ended questions to complement quantitative data
Types of Content Analysis
There are two general types of content analysis: conceptual analysis and relational analysis. Conceptual analysis determines the existence and frequency of concepts in a text. Relational analysis develops the conceptual analysis further by examining the relationships among concepts in a text. Each type of analysis may lead to different results, conclusions, interpretations and meanings.
Conceptual Analysis
Typically people think of conceptual analysis when they think of content analysis. In conceptual analysis, a concept is chosen for examination and the analysis involves quantifying and counting its presence. The main goal is to examine the occurrence of selected terms in the data. Terms may be explicit or implicit. Explicit terms are easy to identify. Coding of implicit terms is more complicated: you need to decide the level of implication and base judgments on subjectivity (issue for reliability and validity). Therefore, coding of implicit terms involves using a dictionary or contextual translation rules or both.
To begin a conceptual content analysis, first identify the research question and choose a sample or samples for analysis. Next, the text must be coded into manageable content categories. This is basically a process of selective reduction. By reducing the text to categories, the researcher can focus on and code for specific words or patterns that inform the research question.
General steps for conducting a conceptual content analysis:
1. Decide the level of analysis: word, word sense, phrase, sentence, themes
2. Decide how many concepts to code for: develop pre-defined or interactive set of categories or concepts. Decide either: A. to allow flexibility to add categories through the coding process, or B. to stick with the pre-defined set of categories.
- Option A allows for the introduction and analysis of new and important material that could have significant implications to one’s research question.
- Option B allows the researcher to stay focused and examine the data for specific concepts.
3. Decide whether to code for existence or frequency of a concept. The decision changes the coding process.
- When coding for the existence of a concept, the researcher would count a concept only once if it appeared at least once in the data and no matter how many times it appeared.
- When coding for the frequency of a concept, the researcher would count the number of times a concept appears in a text.
4. Decide on how you will distinguish among concepts:
- Should text be coded exactly as they appear or coded as the same when they appear in different forms? For example, “dangerous” vs. “dangerousness”. The point here is to create coding rules so that these word segments are transparently categorized in a logical fashion. The rules could make all of these word segments fall into the same category, or perhaps the rules can be formulated so that the researcher can distinguish these word segments into separate codes.
- What level of implication is to be allowed? Words that imply the concept or words that explicitly state the concept? For example, “dangerous” vs. “the person is scary” vs. “that person could cause harm to me”. These word segments may not merit separate categories, due the implicit meaning of “dangerous”.
5. Develop rules for coding your texts. After decisions of steps 1-4 are complete, a researcher can begin developing rules for translation of text into codes. This will keep the coding process organized and consistent. The researcher can code for exactly what he/she wants to code. Validity of the coding process is ensured when the researcher is consistent and coherent in their codes, meaning that they follow their translation rules. In content analysis, obeying by the translation rules is equivalent to validity.
6. Decide what to do with irrelevant information: should this be ignored (e.g. common English words like “the” and “and”), or used to reexamine the coding scheme in the case that it would add to the outcome of coding?
7. Code the text: This can be done by hand or by using software. By using software, researchers can input categories and have coding done automatically, quickly and efficiently, by the software program. When coding is done by hand, a researcher can recognize error far more easily (e.g. typos, misspelling). If using computer coding, text could be cleaned of errors to include all available data. This decision of hand vs. computer coding is most relevant for implicit information where category preparation is essential for accurate coding.
8. Analyze your results: Draw conclusions and generalizations where possible. Determine what to do with irrelevant, unwanted or unused text: reexamine, ignore, or reassess the coding scheme. Interpret results carefully as conceptual content analysis can only quantify the information. Typically, general trends and patterns can be identified.
Relational Analysis
Relational analysis begins like conceptual analysis, where a concept is chosen for examination. However, the analysis involves exploring the relationships between concepts. Individual concepts are viewed as having no inherent meaning and rather the meaning is a product of the relationships among concepts.
To begin a relational content analysis, first identify a research question and choose a sample or samples for analysis. The research question must be focused so the concept types are not open to interpretation and can be summarized. Next, select text for analysis. Select text for analysis carefully by balancing having enough information for a thorough analysis so results are not limited with having information that is too extensive so that the coding process becomes too arduous and heavy to supply meaningful and worthwhile results.
There are three subcategories of relational analysis to choose from prior to going on to the general steps.
- Affect extraction: an emotional evaluation of concepts explicit in a text. A challenge to this method is that emotions can vary across time, populations, and space. However, it could be effective at capturing the emotional and psychological state of the speaker or writer of the text.
- Proximity analysis: an evaluation of the co-occurrence of explicit concepts in the text. Text is defined as a string of words called a “window” that is scanned for the co-occurrence of concepts. The result is the creation of a “concept matrix”, or a group of interrelated co-occurring concepts that would suggest an overall meaning.
- Cognitive mapping: a visualization technique for either affect extraction or proximity analysis. Cognitive mapping attempts to create a model of the overall meaning of the text such as a graphic map that represents the relationships between concepts.
General steps for conducting a relational content analysis:
1. Determine the type of analysis: Once the sample has been selected, the researcher needs to determine what types of relationships to examine and the level of analysis: word, word sense, phrase, sentence, themes.
2. Reduce the text to categories and code for words or patterns. A researcher can code for existence of meanings or words.
3. Explore the relationship between concepts: once the words are coded, the text can be analyzed for the following:
- Strength of relationship: degree to which two or more concepts are related.
- Sign of relationship: are concepts positively or negatively related to each other?
- Direction of relationship: the types of relationship that categories exhibit. For example, “X implies Y” or “X occurs before Y” or “if X then Y” or if X is the primary motivator of Y.
4. Code the relationships: a difference between conceptual and relational analysis is that the statements or relationships between concepts are coded.
5. Perform statistical analyses: explore differences or look for relationships among the identified variables during coding.
6. Map out representations: such as decision mapping and mental models.
Reliability and Validity
Reliability: Because of the human nature of researchers, coding errors can never be eliminated but only minimized. Generally, 80% is an acceptable margin for reliability. Three criteria comprise the reliability of a content analysis:
- Stability: the tendency for coders to consistently re-code the same data in the same way over a period of time.
- Reproducibility: tendency for a group of coders to classify categories membership in the same way.
- Accuracy: extent to which the classification of text corresponds to a standard or norm statistically.
Validity: Three criteria comprise the validity of a content analysis:
- Closeness of categories: this can be achieved by utilizing multiple classifiers to arrive at an agreed upon definition of each specific category. Using multiple classifiers, a concept category that may be an explicit variable can be broadened to include synonyms or implicit variables.
- Conclusions: What level of implication is allowable? Do conclusions correctly follow the data? Are results explainable by other phenomena? This becomes especially problematic when using computer software for analysis and distinguishing between synonyms. For example, the word “mine,” variously denotes a personal pronoun, an explosive device, and a deep hole in the ground from which ore is extracted. Software can obtain an accurate count of that word’s occurrence and frequency, but not be able to produce an accurate accounting of the meaning inherent in each particular usage. This problem could throw off one’s results and make any conclusion invalid.
- Generalizability of the results to a theory: dependent on the clear definitions of concept categories, how they are determined and how reliable they are at measuring the idea one is seeking to measure. Generalizability parallels reliability as much of it depends on the three criteria for reliability.
Advantages of Content Analysis
- Directly examines communication using text
- Allows for both qualitative and quantitative analysis
- Provides valuable historical and cultural insights over time
- Allows a closeness to data
- Coded form of the text can be statistically analyzed
- Unobtrusive means of analyzing interactions
- Provides insight into complex models of human thought and language use
- When done well, is considered a relatively “exact” research method
- Content analysis is a readily-understood and an inexpensive research method
- A more powerful tool when combined with other research methods such as interviews, observation, and use of archival records. It is very useful for analyzing historical material, especially for documenting trends over time.
Disadvantages of Content Analysis
- Can be extremely time consuming
- Is subject to increased error, particularly when relational analysis is used to attain a higher level of interpretation
- Is often devoid of theoretical base, or attempts too liberally to draw meaningful inferences about the relationships and impacts implied in a study
- Is inherently reductive, particularly when dealing with complex texts
- Tends too often to simply consist of word counts
- Often disregards the context that produced the text, as well as the state of things after the text is produced
-
Can be difficult to automate or computerize
18 Aug 2021
18 Aug 2021
18 Aug 2021
18 Aug 2021
18 Aug 2021
18 Aug 2021