One of the advantages of SEM is that you can assess if your model is “fitting” the data or, specifically, the observed covariance matrix.The term “model fit” denotes that your specified model (estimated covariance matrix) is a close representation of the data (observed covari- ance matrix). A bad fit, on the other hand, indicates that the data is contrary to the specified model. The model fit test is to understand how the total structure of the model fits the data. A good model fit does not mean that every particular part of the model fits well. Again, the test of model fit is looking at the overall model compared to the data. One caution with assessing model fit is that a model with fewer indicators per factor will have a higher apparent fit than a model with more indicators per factor. Model fit coefficients reward parsimony. Thus, if you have a complex model, you will find it more difficult to achieve a “good model fit” compared to a more simplistic model.
The AMOS software will give you a plethora of model fit statistics. There are more than 20 different model fit tests, but I will discuss only the prominent ones seen in most research. Model Chi-Square Test: the chi-square test is also called the chi-square goodness of fit test, but in reality, chi-square is a “badness of fit” measure. The chi-square value should not be significant if there is a good model fit. A significance means your model’s covariance struc- ture is significantly different from the observed covariance matrix of the data. If chi-square is <.05, then your model is considered to be ill-fitting. Saying that, a simple chi-square test is problematic for a number of reasons. First, the closer you are to a just-identified model, the better the model fit.You are penalized for having a complex model. Second, chi-square is very sensitive to sample size. In very large samples, even tiny differences between the observed model and the perfect fit model may be found. A better option with chi-square is to use a “relative chi-square” test, which is the chi-square value divided by the degrees of freedom, thus making it less dependent on sample size. Kline (2011) states that a relative chi-square test with a value under 3 is considered acceptable fit. I have seen some research- ers say that values as high as 5 are okay (Schumacker and Lomax 2004). Conversely, some researchers state that a value less than 1 is considered “overfitting” and a sign of poor fit (Byrne 1989). Ultimately, reporting chi-square and the degrees of freedom is always advis- able when presenting model fit statistics.
Comparative Statistics: these type of model fit statistics (also called an incremental fit statis- tics) compare competing models to determine which provides a better fit.
Null Model: many of the fit indices require a test (comparison) to be done against a “null model”. The default “null model” in AMOS allows the correlations among observed variables to be constrained to 0 (implying that the latent variables are also uncorrelated).The means and variances of the measured variables are also unconstrained.
Comparative Fit Index (CFI): this test compares the covariance matrix predicted by your model to the observed covariance matrix of the null model. CFI varies from 0 to 1. A CFI value close to 1 indicates a good fit. The cutoff for an acceptable fit for a CFI value is > .90 (Bentler and Bonett 1980)—indicating that 90% of the covariation in the data can be repro- duced by your model. CFI is not affected by sample size and is a recommend fit statistic to report.
Incremental Fit Index (IFI): this is calculated by (chi-square for the null model − chi-square for your model)/(chi-square for the null model − degrees of freedom for your model). IFI should be .90 or higher to have an acceptable fit. IFI is relatively independent to sample size and is one that is frequently reported.
Normed Fit Index (NFI): this is calculated by (chi-square for the null model − chi-square for your model)/(chi-square for the null model). An NFI statistic equal to .50 means your model improves fit by 50% compared to the null model. An acceptable fit is above .90 or above. Note that NFI may underestimate fit for small samples and does not reflect parsimony (the more parameters in the model, the larger the NFI).
Tucker Lewis Index (TLI): this fit index is also called the Non-Normed Fit Index. It is cal- culated by (chi-square for the null model − chi-square for your model)/(chi-square for the null model/degrees of freedom for your model − 1). As with the other fit indices, above .90 equals an acceptable fit.
Relative Fit Index (RFI): this is calculated by (chi-square for your model/degrees of freedom for your model)/(chi-square for the null model/degrees of freedom for your model). RFI close to 1 indicates a good fit. Acceptable fit is .90 and above.
Root Mean Square Error of Approximation (RMSEA): This is a “badness of fit” test where values close to “0” equal the best fit. A good model fit is present if RMSEA is below .05. There is an adequate fit if it is .08 and below—values over .10 denote a poor fit (MacCal- lum et al. 1996). AMOS will also give you a 90% confidence interval of the RMSEA value. Instead of just examining a single estimate, examining confidence intervals will provide more information on the acceptability of the model to the data. If your RMSEA value is .06, this value initially appears to be an adequate fitting model. If you examine the confidence intervals and see that the lower bound is .04 and the upper bound is .16, then you can see that the fit is not as good as you once thought when simply viewing only the RMSEA value. This wide range in the confidence interval lets you know that the initial estimate may not be a very accurate determination of model fit. Conversely, if the confidence interval is small around your initial estimate, then you can conclude that the RMSEA value is quite precise in regard to model fit.
Unlike some of the other model fit assessments, the RMSEA test does not compare against the null model but is calculated by:
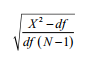
Standardized Root Mean Square Residual (SRMR): this is the average difference between the predicted and observed covariances in the model based on standardized residuals. Like RMSEA, this is a badness of fit test in which the bigger the value, the worse the fit. A SRMR of .05 and below is considered a good fit and a fit of .05 to .09 is considered an adequate fit (MacCallum et al. 1996). This fit statistic has to be specially requested in AMOS compared to other fit statistics that are presented in the analysis. To request this in AMOS, you need to select the “Plugin” tab at the top menu screen and then select “Stand- ard RMR”.
Goodness-of-Fit Index and Adjusted Goodness-of-Fit Index (GFI/AGFI): not to be confused with the other indices that examine the “goodness of fit” of a model to the data, this index with the name of goodness-of-fit index and adjusted goodness-of-fit index were initially created as another option to understand the proportion of variance being captured in the estimated covariance matrix. While this index was quite popular in its infancy, it was shown to be problematic because of its sensitivity to sample size (Sharma et al. 2005). As well, these indices were not very responsive to identifying misspecified models. Thus, the growing consensus was that these specific indices needed to be avoided (Hu and Bentler 1999).
What Value Means the Model Is a Good Fit?
There is no shortage of controversy on what should be the cutoff criteria for these fit indices discussed. Bentler and Bonett (1980) is the most widely cited research encouraging research- ers to pursue model fit statistics (CFI, TLI, NFI, IFI) that are greater than .90. This rule of thumb became widely accepted even though researchers such as Hu and Bentler (1999) argued that a .90 criteria was too liberal and that fit indices needed to be greater than .95 to be considered a good-fitting model. Subsequently, Marsh et al. (2004) have argued against the rigorous Hu and Bentler criteria in favor of using multiple indices based on the sample size, estimators or distributions. Hence, there are no golden rules that universally hold as it per- tains to model fit. The criteria outlined in this section is based on the existing literature and provides guidance on what is an “acceptable” model fit to the data. Even if a researcher exceeds the .90 threshold for a model fit index, one should use caution in stating a model is a “good” fit. Kline (2011) notes that even if a model is deemed to have a passable model fit, it does not mean that it is correctly specified. A so-called “good-fitting” model can still poorly explain the relationships in a model.
Let me be clear: model fit indices have value, and it is still an important step in the analysis. If you can pass the initial step of assessing if the observed covariance matrix and estimated covariance matrix are similar, then you have initial evidence that the model is appropriately specified. Again, it should be a first step in making that determination based on not only model fit but also the parameters and relationships that need to be estimated.
Source: Thakkar, J.J. (2020). “Procedural Steps in Structural Equation Modelling”. In: Structural Equation Modelling. Studies in Systems, Decision and Control, vol 285. Springer, Singapore.
29 Mar 2023
28 Mar 2023
31 Mar 2023
28 Mar 2023
31 Mar 2023
28 Mar 2023