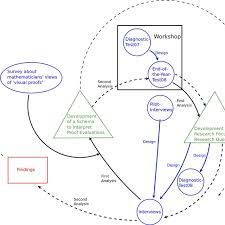
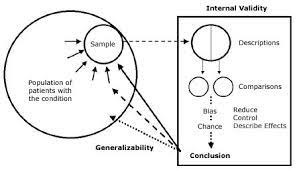
The Translation Process of the Research
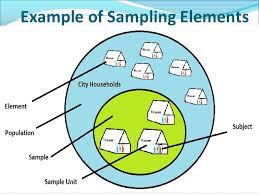
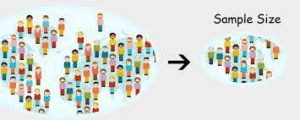
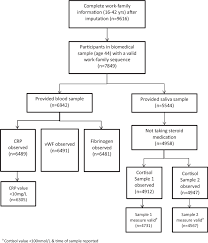
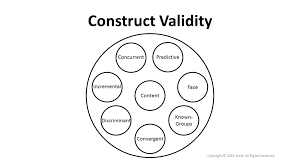
In this section we introduce and outline the principle elements that characterize the translation process. 1. Concepts and Data 1.1. The theoretical realm The theoretical realm encompasses all the knowledge, concepts, models and theories available, or in the process of being constructed, in the literature on a subject. With respect to translation, however, researchers