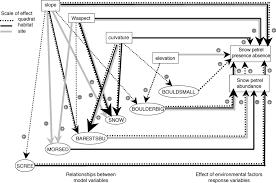
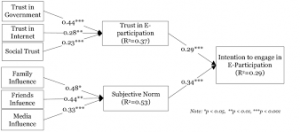
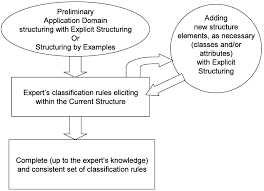
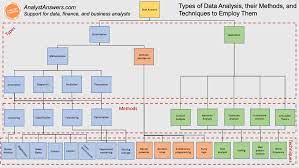
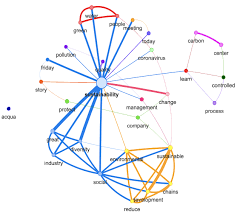
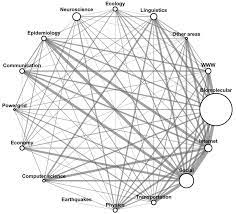
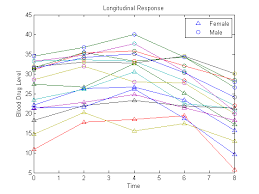
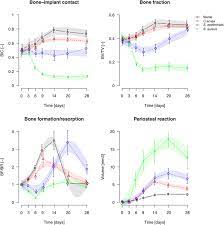
Specifying Variables and Concepts of the Research
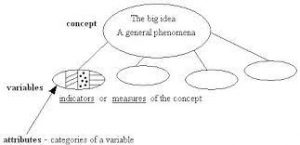
Specifying a model’s different concepts and variables is, above all, dependent on the researcher’s chosen approach, which can be inductive or deductive, qualitative or quantitative. There are two levels of specification. One is conceptual, and enables researchers to determine the nature of concepts. The other is operational, and enables researchers to move from concepts