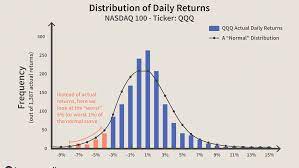
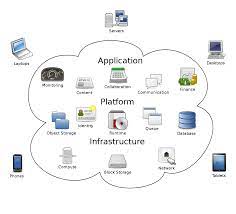
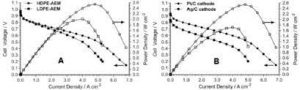
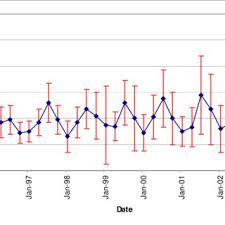
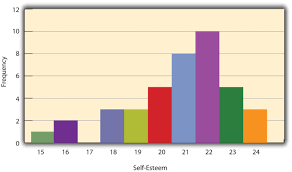
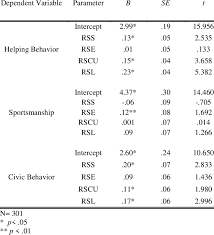
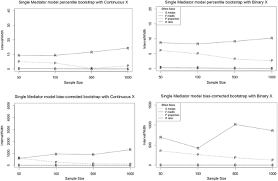
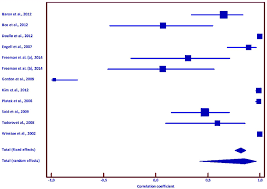
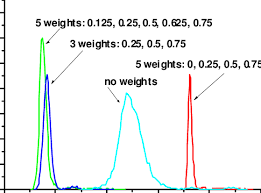
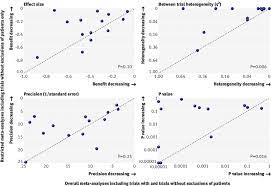
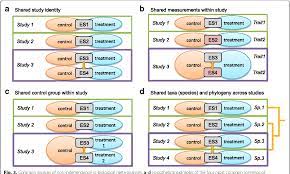
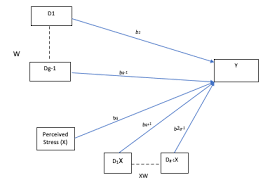
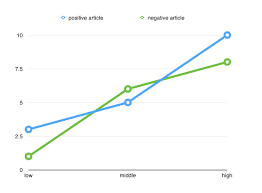
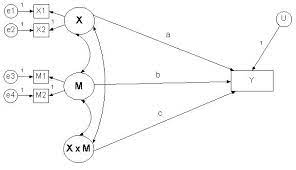
Comparisons among r, g, and o
I have emphasized the importance of basing the decision to rely on r, g, or o on conceptualizations of the association involving two continuous variables, a dichotomous and a continuous variable, or two dichotomous variables, respectively. At the same time, it can be useful to understand that you can compute values of one effect