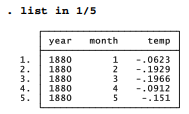
Many Stata commands can be restricted to a subset of the data by adding an in or if qualifier. Qualifiers are also available for many menu selections: look for an if/in or by/if/in tab along the top of the dialog. in specifies the observation numbers to which the command applies. For example, list in 5 tells Stata to list only the 5th observation. To list the 1st through 5th observations, type
The letter l denotes the last case, and -10 , for example, the tenth-from-last. Among the 1,584 months in our global temperature data, which 10 months had the highest temperature anomalies, meaning they were farthest above the 1901-2000 average for that month? To find out, we first sort from lowest to highest by temperature, then list the 10th-from-last to last observations:
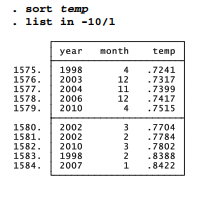
Note the important, although typographically subtle, distinction between 1 (number one, or first observation) and l (letter “el,” or last observation). The in qualifier works in a similar way with most other analytical or data-editing commands. It always refers to the data as presently sorted.
The if qualifier also has broad applications, but it selects observations based on specific variable values. For example, to see the mean and standard deviation of temperature anomalies prior to 1970, type
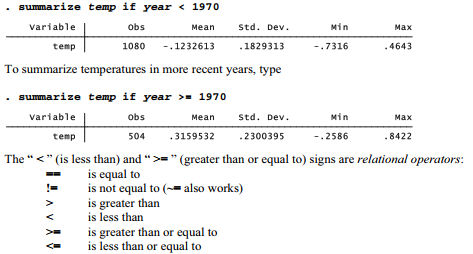
A double equals sign, “ == ”, denotes the logical test, “Is the value on the left side the same as the value on the right?” To Stata, a single equals sign means something different: “Make the value on the left side be the same as the value on the right.” The single equals sign is not a relational operator and cannot be used within if qualifiers. Single equals signs have other meanings. They are used with commands that generate new variables, or replace the values of old ones, according to algebraic expressions. Single equals signs also appear in certain specialized applications such as weighting and hypothesis tests.
Two or more relational operators can be combined within a single if expression by the use of logical operators. Stata’s logical operators are the following:
& and
| or (symbol is a vertical bar, not the number one or letter “el”)
! not (~ also works)
Parentheses allow us to specify the precedence among multiple operators. The following command will summarize January and February temperature anomalies for the years from 1940 through 1969:
. summarize temp if (month == 1 | month == 2) & year > = 1940 & year < 1970
A note of caution regarding missing values: Stata ordinarily shows missing values as a period, but in some operations (notably sort and if, although not in statistical calculations such as means
or correlations), these same missing values are treated as if they were large positive numbers. For example, suppose that we are analyzing opinion poll data. A command such as the following would tabulate vote not only for people age 65 and older, as intended, but also for any people whose age values are missing:
. tabulate vote if age >= 65
Where missing values exist, we often need to deal with them explicitly in the if expression.
. tabulate vote if age >= 65 & !missing(age)
The not missing() function !missing( ) provides a general way to select observations with nonmissing values. As shown later in this chapter, Stata permits up to 27 different missing values codes, although so far we have used only the default “ . ”. if !missing(«ge) sets them all aside. Type help missing for more details.
There are several alternative ways to screen out missing values. The missing( ) function evaluates to 1 if a value is missing, and 0 if it is not. For example, to tabulate vote only for those observations that have nonmissing values of age, income and education, type
. tabulate vote if missing(age, Income, educatlon)==Q
Finally, because the default missing value “.” is represented internally by a very large number, and other missing values (described later) are even larger, a “less than” inequality <. can be used to screen all of them out:
. tabulate vote if age <. & Income <. & education <.
The in and if qualifiers set observations aside temporarily so that a particular command does not apply to them. These qualifiers have no effect on the data in memory, and the next command will apply to all observations unless it too has an in or if qualifier. To drop variables from the data in memory, use the drop command (or use the Data Editor). Returning to our Canadian data (Canadal.dta), we could drop mlife and flife from memory by typing
. drop mlife flife
Either in or if qualifiers can be used to select which observations to drop. For example, drop in 12/13 means to drop the 12th and 13th observation in a dataset. We can also drop selected variables or observations with the Delete button in the Data Editor.
Instead of telling Stata which variables or observations to drop, it sometimes is simpler to specify which to keep. Rather than drop mlife and flife from the Canadal.dta data, we accomplish the same thing if we keep the other three variables.
. keep place pop unemp
Like any other changes to the data in memory, none of these reductions affect disk files until we save the data. At that point, we will have the option of writing over the old dataset (save, replace) and thus destroying it, or just saving the newly modified dataset with a new name (by choosing File > Save As , or by typing a command with the form save newname ) so that both versions exist on disk.
Source: Hamilton Lawrence C. (2012), Statistics with STATA: Version 12, Cengage Learning; 8th edition.
24 Sep 2022
3 Oct 2022
1 Oct 2022
3 Oct 2022
3 Oct 2022
24 Sep 2022