Stata Documentation and Resources
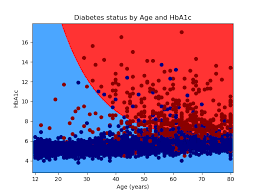
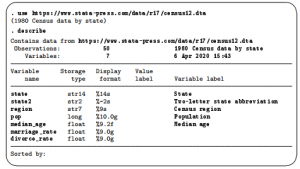
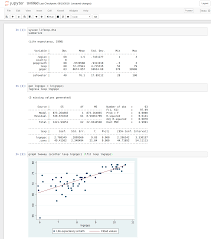
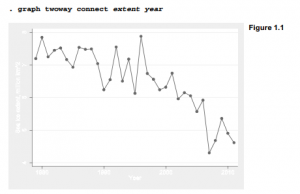
1. Stata’s Documentation and Help Files The complete Stata 12 Documentation Set includes 19 volumes: a slim Getting Started manual (for example, Getting Started with Stata for Windows), the more extensive User’s Guide, the encyclopedic four-volume Base Reference Manual, and separate reference manuals on data management, graphics, longitudinal and panel data, matrix programming (Mata),