Creative Graphing by using Stata
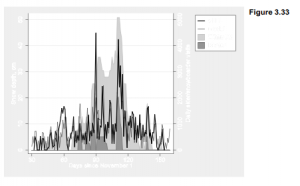
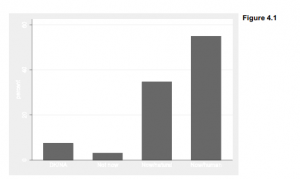
Edward Tufte, in his elegant and influential books about graphing data (1990, 1997, 2001, 2006), calls for more effort at designing clear, information-packed graphics. Presenting a rich collection of impressively good or humorously awful examples, Tufte shows how successful graphics allow viewers to draw their own comparisons and examine details of relationships between variables.