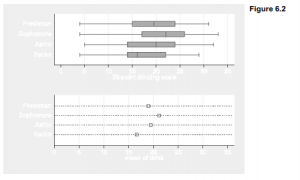
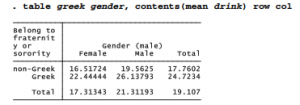
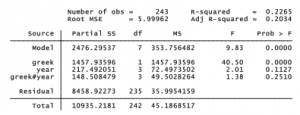
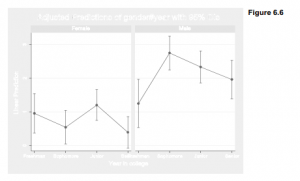
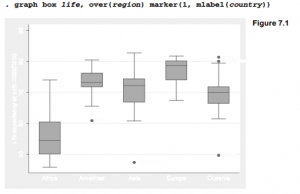
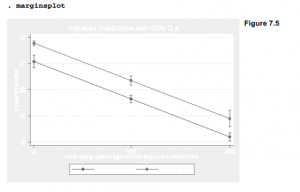
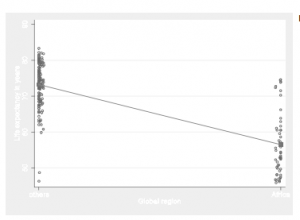
Multiple Tables and Multi-Way Cross-Tabulations by using Stata
With surveys and other large datasets, we sometimes need frequency distributions of many different variables. Instead of asking for each table separately, for example by typing tabulate tparty, then tabulate obama, and finally tabulate trackus, we could simply use another specialized command, tabl: . tabl tparty obama trackus Or, to produce one-way frequency tables