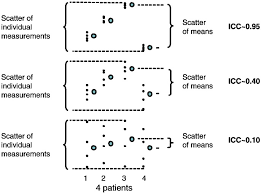
Comparing Two Groups with SPSS – Problem 9.3: The Nonparametric Mann-Whitney U Test
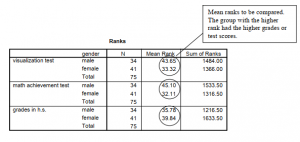
What should you do if the t test assumptions are markedly violated (e.g., what if the dependent variable data are grossly skewed, otherwise non-normally distributed, or are ordinal)? One answer is to run the appropriate nonparametric statistic, which in this case is called the Mann-Whitney (M-W) U test. The M-W is used with a